Test Descriptions
Short name
dovetail.ipv6.tc001.bulk_network_subnet_port_create_delete
Use case specification
This test case evaluates the SUT API ability of creating and deleting multiple networks,
IPv6 subnets, ports in one request, the reference is,
tempest.api.network.test_networks.BulkNetworkOpsIpV6Test.test_bulk_create_delete_network
tempest.api.network.test_networks.BulkNetworkOpsIpV6Test.test_bulk_create_delete_subnet
tempest.api.network.test_networks.BulkNetworkOpsIpV6Test.test_bulk_create_delete_port
Basic test flow execution description and pass/fail criteria
- Test action 1: Create 2 networks using bulk create, storing the “id” parameters returned in the response
- Test action 2: List all networks, verifying the two network id’s are found in the list
- Test assertion 1: The two “id” parameters are found in the network list
- Test action 3: Delete the 2 created networks using the stored network ids
- Test action 4: List all networks, verifying the network ids are no longer present
- Test assertion 2: The two “id” parameters are not present in the network list
- Test action 5: Create 2 networks using bulk create, storing the “id” parameters returned in the response
- Test action 6: Create an IPv6 subnets on each of the two networks using bulk create commands,
storing the associated “id” parameters
- Test action 7: List all subnets, verify the IPv6 subnets are found in the list
- Test assertion 3: The two IPv6 subnet “id” parameters are found in the network list
- Test action 8: Delete the 2 IPv6 subnets using the stored “id” parameters
- Test action 9: List all subnets, verify the IPv6 subnets are no longer present in the list
- Test assertion 4: The two IPv6 subnet “id” parameters, are not present in list
- Test action 10: Delete the 2 networks created in test action 5, using the stored network ids
- Test action 11: List all networks, verifying the network ids are no longer present
- Test assertion 5: The two “id” parameters are not present in the network list
- Test action 12: Create 2 networks using bulk create, storing the “id” parameters returned in the response
- Test action 13: Create a port on each of the two networks using bulk create commands,
storing the associated “port_id” parameters
- Test action 14: List all ports, verify the port_ids are found in the list
- Test assertion 6: The two “port_id” parameters are found in the ports list
- Test action 15: Delete the 2 ports using the stored “port_id” parameters
- Test action 16: List all ports, verify port_ids are no longer present in the list
- Test assertion 7: The two “port_id” parameters, are not present in list
- Test action 17: Delete the 2 networks created in test action 12, using the stored network ids
- Test action 18: List all networks, verifying the network ids are no longer present
- Test assertion 8: The two “id” parameters are not present in the network list
This test evaluates the ability to use bulk create commands to create networks, IPv6 subnets and ports on
the SUT API. Specifically it verifies that:
- Bulk network create commands return valid “id” parameters which are reported in the list commands
- Bulk IPv6 subnet commands return valid “id” parameters which are reported in the list commands
- Bulk port commands return valid “port_id” parameters which are reported in the list commands
- All items created using bulk create commands are able to be removed using the returned identifiers
Post conditions
N/A
Test Case 2 - Create, Update and Delete an IPv6 Network and Subnet
Short name
dovetail.ipv6.tc002.network_subnet_create_update_delete
Use case specification
This test case evaluates the SUT API ability of creating, updating, deleting
network and IPv6 subnet with the network, the reference is
tempest.api.network.test_networks.NetworksIpV6Test.test_create_update_delete_network_subnet
Basic test flow execution description and pass/fail criteria
- Test action 1: Create a network, storing the “id” and “status” parameters returned
in the response
- Test action 2: Verify the value of the created network’s “status” is ACTIVE
- Test assertion 1: The created network’s “status” is ACTIVE
- Test action 3: Update this network with a new_name
- Test action 4: Verify the network’s name equals the new_name
- Test assertion 2: The network’s name equals to the new_name after name updating
- Test action 5: Create an IPv6 subnet within the network, storing the “id” parameters
returned in the response
- Test action 6: Update this IPv6 subnet with a new_name
- Test action 7: Verify the IPv6 subnet’s name equals the new_name
- Test assertion 3: The IPv6 subnet’s name equals to the new_name after name updating
- Test action 8: Delete the IPv6 subnet created in test action 5, using the stored subnet id
- Test action 9: List all subnets, verifying the subnet id is no longer present
- Test assertion 4: The IPv6 subnet “id” is not present in the subnet list
- Test action 10: Delete the network created in test action 1, using the stored network id
- Test action 11: List all networks, verifying the network id is no longer present
- Test assertion 5: The network “id” is not present in the network list
This test evaluates the ability to create, update, delete network, IPv6 subnet on the
SUT API. Specifically it verifies that:
- Create network commands return ACTIVE “status” parameters which are reported in the list commands
- Update network commands return updated “name” parameters which equals to the “name” used
- Update subnet commands return updated “name” parameters which equals to the “name” used
- All items created using create commands are able to be removed using the returned identifiers
Post conditions
None
Test Case 3 - Check External Network Visibility
Short name
dovetail.ipv6.tc003.external_network_visibility
Use case specification
This test case verifies user can see external networks but not subnets, the reference is,
tempest.api.network.test_networks.NetworksIpV6Test.test_external_network_visibility
Test preconditions
- The SUT has at least one external network.
2. In the external network list, there is no network without external router, i.e.,
all networks in this list are with external router.
3. There is one external network with configured public network id and there is
no subnet on this network
Basic test flow execution description and pass/fail criteria
- Test action 1: List all networks with external router, storing the “id”s parameters returned in the response
- Test action 2: Verify list in test action 1 is not empty
- Test assertion 1: The network with external router list is not empty
- Test action 3: List all netowrks without external router in test action 1 list
- Test action 4: Verify list in test action 3 is empty
- Test assertion 2: networks without external router in the external network
list is empty
- Test action 5: Verify the configured public network id is found in test action 1 stored “id”s
- Test assertion 3: the public network id is found in the external network “id”s
- Test action 6: List the subnets of the external network with the configured
public network id
- Test action 7: Verify list in test action 6 is empty
- Test assertion 4: There is no subnet of the external network with the configured
public network id
This test evaluates the ability to use list commands to list external networks, pre-configured
public network. Specifically it verifies that:
- Network list commands to find visible networks with external router
- Network list commands to find visible network with pre-configured public network id
- Subnet list commands to find no subnet on the pre-configured public network
Post conditions
None
Test Case 4 - List IPv6 Networks and Subnets
Short name
dovetail.ipv6.tc004.network_subnet_list
Use case specification
This test case evaluates the SUT API ability of listing netowrks,
subnets after creating a network and an IPv6 subnet, the reference is
tempest.api.network.test_networks.NetworksIpV6Test.test_list_networks
tempest.api.network.test_networks.NetworksIpV6Test.test_list_subnets
Basic test flow execution description and pass/fail criteria
- Test action 1: Create a network, storing the “id” parameter returned in the response
- Test action 2: List all networks, verifying the network id is found in the list
- Test assertion 1: The “id” parameter is found in the network list
- Test action 3: Create an IPv6 subnet of the network created in test action 1.
storing the “id” parameter returned in the response
- Test action 4: List all subnets of this network, verifying the IPv6 subnet id
is found in the list
- Test assertion 2: The “id” parameter is found in the IPv6 subnet list
- Test action 5: Delete the IPv6 subnet using the stored “id” parameters
- Test action 6: List all subnets, verify subnet_id is no longer present in the list
- Test assertion 3: The IPv6 subnet “id” parameter is not present in list
- Test action 7: Delete the network created in test action 1, using the stored network ids
- Test action 8: List all networks, verifying the network id is no longer present
- Test assertion 4: The network “id” parameter is not present in the network list
This test evaluates the ability to use create commands to create network, IPv6 subnet, list
commands to list the created networks, IPv6 subnet on the SUT API. Specifically it verifies that:
- Create commands to create network, IPv6 subnet
- List commands to find that netowrk, IPv6 subnet in the all networks, subnets list after creating
- All items created using create commands are able to be removed using the returned identifiers
Post conditions
None
Test Case 5 - Show Details of an IPv6 Network and Subnet
Short name
dovetail.ipv6.tc005.network_subnet_show
Use case specification
This test case evaluates the SUT API ability of showing the network, subnet
details, the reference is,
tempest.api.network.test_networks.NetworksIpV6Test.test_show_network
tempest.api.network.test_networks.NetworksIpV6Test.test_show_subnet
Basic test flow execution description and pass/fail criteria
- Test action 1: Create a network, storing the “id” and “name” parameter returned in the response
- Test action 2: Show the network id and name, verifying the network id and name equal to the
“id” and “name” stored in test action 1
- Test assertion 1: The id and name equal to the “id” and “name” stored in test action 1
- Test action 3: Create an IPv6 subnet of the network, storing the “id” and CIDR parameter
returned in the response
- Test action 4: Show the details of the created IPv6 subnet, verifying the
id and CIDR in the details are equal to the stored id and CIDR in test action 3.
- Test assertion 2: The “id” and CIDR in show details equal to “id” and CIDR stored in test action 3
- Test action 5: Delete the IPv6 subnet using the stored “id” parameter
- Test action 6: List all subnets on the network, verify the IPv6 subnet id is no longer present in the list
- Test assertion 3: The IPv6 subnet “id” parameter is not present in list
- Test action 7: Delete the network created in test action 1, using the stored network id
- Test action 8: List all networks, verifying the network id is no longer present
- Test assertion 4: The “id” parameter is not present in the network list
This test evaluates the ability to use create commands to create network, IPv6 subnet and show
commands to show network, IPv6 subnet details on the SUT API. Specifically it verifies that:
- Network show commands return correct “id” and “name” parameter which equal to the returned response in the create commands
- IPv6 subnet show commands return correct “id” and CIDR parameter which equal to the returned response in the create commands
- All items created using create commands are able to be removed using the returned identifiers
Post conditions
None
Test Case 6 - Create an IPv6 Port in Allowed Allocation Pools
Short name
dovetail.ipv6.tc006.port_create_in_allocation_pool
Use case specification
This test case evaluates the SUT API ability of creating
an IPv6 subnet within allowed IPv6 address allocation pool and creating
a port whose address is in the range of the pool, the reference is,
tempest.api.network.test_ports.PortsIpV6TestJSON.test_create_port_in_allowed_allocation_pools
Test preconditions
There should be an IPv6 CIDR configuration, which prefixlen is less than 126.
Basic test flow execution description and pass/fail criteria
- Test action 1: Create a network, storing the “id” parameter returned in the response
- Test action 2: Check the allocation pools configuration, verifying the prefixlen
of the IPv6 CIDR configuration is less than 126.
- Test assertion 1: The prefixlen of the IPv6 CIDR configuration is less than 126
- Test action 3: Get the allocation pool by setting the start_ip and end_ip
based on the IPv6 CIDR configuration.
- Test action 4: Create an IPv6 subnet of the network within the allocation pools,
storing the “id” parameter returned in the response
- Test action 5: Create a port of the network, storing the “id” parameter returned in the response
- Test action 6: Verify the port’s id is in the range of the allocation pools which is got is test action 3
- Test assertion 2: the port’s id is in the range of the allocation pools
- Test action 7: Delete the port using the stored “id” parameter
- Test action 8: List all ports, verify the port id is no longer present in the list
- Test assertion 3: The port “id” parameter is not present in list
- Test action 9: Delete the IPv6 subnet using the stored “id” parameter
- Test action 10: List all subnets on the network, verify the IPv6 subnet id is no longer present in the list
- Test assertion 4: The IPv6 subnet “id” parameter is not present in list
- Test action 11: Delete the network created in test action 1, using the stored network id
- Test action 12: List all networks, verifying the network id is no longer present
- Test assertion 5: The “id” parameter is not present in the network list
This test evaluates the ability to use create commands to create an IPv6 subnet within allowed
IPv6 address allocation pool and create a port whose address is in the range of the pool. Specifically it verifies that:
- IPv6 subnet create command to create an IPv6 subnet within allowed IPv6 address allocation pool
- Port create command to create a port whose id is in the range of the allocation pools
- All items created using create commands are able to be removed using the returned identifiers
Post conditions
None
Test Case 7 - Create an IPv6 Port with Empty Security Groups
Short name
dovetail.ipv6.tc007.port_create_empty_security_group
Use case specification
This test case evaluates the SUT API ability of creating port with empty
security group, the reference is,
tempest.api.network.test_ports.PortsIpV6TestJSON.test_create_port_with_no_securitygroups
Basic test flow execution description and pass/fail criteria
- Test action 1: Create a network, storing the “id” parameter returned in the response
- Test action 2: Create an IPv6 subnet of the network, storing the “id” parameter returned in the response
- Test action 3: Create a port of the network with an empty security group, storing the “id” parameter returned in the response
- Test action 4: Verify the security group of the port is not none but is empty
- Test assertion 1: the security group of the port is not none but is empty
- Test action 5: Delete the port using the stored “id” parameter
- Test action 6: List all ports, verify the port id is no longer present in the list
- Test assertion 2: The port “id” parameter is not present in list
- Test action 7: Delete the IPv6 subnet using the stored “id” parameter
- Test action 8: List all subnets on the network, verify the IPv6 subnet id is no longer present in the list
- Test assertion 3: The IPv6 subnet “id” parameter is not present in list
- Test action 9: Delete the network created in test action 1, using the stored network id
- Test action 10: List all networks, verifying the network id is no longer present
- Test assertion 4: The “id” parameter is not present in the network list
This test evaluates the ability to use create commands to create port with
empty security group of the SUT API. Specifically it verifies that:
- Port create commands to create a port with an empty security group
- All items created using create commands are able to be removed using the returned identifiers
Post conditions
None
Test Case 8 - Create, Update and Delete an IPv6 Port
Short name
dovetail.ipv6.tc008.port_create_update_delete
Use case specification
This test case evaluates the SUT API ability of creating, updating,
deleting IPv6 port, the reference is,
tempest.api.network.test_ports.PortsIpV6TestJSON.test_create_update_delete_port
Basic test flow execution description and pass/fail criteria
- Test action 1: Create a network, storing the “id” parameter returned in the response
- Test action 2: Create a port of the network, storing the “id” and “admin_state_up” parameters
returned in the response
- Test action 3: Verify the value of port’s ‘admin_state_up’ is True
- Test assertion 1: the value of port’s ‘admin_state_up’ is True after creating
- Test action 4: Update the port’s name with a new_name and set port’s admin_state_up to False,
storing the name and admin_state_up parameters returned in the response
- Test action 5: Verify the stored port’s name equals to new_name and the port’s admin_state_up is False.
- Test assertion 2: the stored port’s name equals to new_name and the port’s admin_state_up is False
- Test action 6: Delete the port using the stored “id” parameter
- Test action 7: List all ports, verify the port is no longer present in the list
- Test assertion 3: The port “id” parameter is not present in list
- Test action 8: Delete the network created in test action 1, using the stored network id
- Test action 9: List all networks, verifying the network id is no longer present
- Test assertion 4: The “id” parameter is not present in the network list
This test evaluates the ability to use create/update/delete commands to create/update/delete port
of the SUT API. Specifically it verifies that:
- Port create commands return True of ‘admin_state_up’ in response
- Port update commands to update ‘name’ to new_name and ‘admin_state_up’ to false
- All items created using create commands are able to be removed using the returned identifiers
Post conditions
None
Test Case 9 - List IPv6 Ports
Short name
dovetail.ipv6.tc009.port_list
Use case specification
This test case evaluates the SUT ability of creating a port on a network and
finding the port in the all ports list, the reference is,
tempest.api.network.test_ports.PortsIpV6TestJSON.test_list_ports
Basic test flow execution description and pass/fail criteria
- Test action 1: Create a network, storing the “id” parameter returned in the response
- Test action 2: Create a port of the network, storing the “id” parameter returned in the response
- Test action 3: List all ports, verify the port id is found in the list
- Test assertion 1: The “id” parameter is found in the port list
- Test action 4: Delete the port using the stored “id” parameter
- Test action 5: List all ports, verify the port is no longer present in the list
- Test assertion 2: The port “id” parameter is not present in list
- Test action 6: Delete the network created in test action 1, using the stored network id
- Test action 7: List all networks, verifying the network id is no longer present
- Test assertion 3: The “id” parameter is not present in the network list
This test evaluates the ability to use list commands to list the networks and ports on
the SUT API. Specifically it verifies that:
- Port list command to list all ports, the created port is found in the list.
- All items created using create commands are able to be removed using the returned identifiers
Post conditions
None
Test Case 10 - Show Key/Valus Details of an IPv6 Port
Short name
dovetail.ipv6.tc010.port_show_details
Use case specification
This test case evaluates the SUT ability of showing the port
details, the values in the details should be equal to the values to create the port,
the reference is,
tempest.api.network.test_ports.PortsIpV6TestJSON.test_show_port
Basic test flow execution description and pass/fail criteria
- Test action 1: Create a network, storing the “id” parameter returned in the response
- Test action 2: Create a port of the network, storing the “id” parameter returned in the response
- Test action 3: Show the details of the port, verify the stored port’s id
in test action 2 exists in the details
- Test assertion 1: The “id” parameter is found in the port shown details
- Test action 4: Verify the values in the details of the port are the same as the values
to create the port
- Test assertion 2: The values in the details of the port are the same as the values
to create the port
- Test action 5: Delete the port using the stored “id” parameter
- Test action 6: List all ports, verify the port is no longer present in the list
- Test assertion 3: The port “id” parameter is not present in list
- Test action 7: Delete the network created in test action 1, using the stored network id
- Test action 8: List all networks, verifying the network id is no longer present
- Test assertion 4: The “id” parameter is not present in the network list
This test evaluates the ability to use show commands to show port details on the SUT API.
Specifically it verifies that:
- Port show commands to show the details of the port, whose id is in the details
- Port show commands to show the details of the port, whose values are the same as the values
to create the port
- All items created using create commands are able to be removed using the returned identifiers
Post conditions
None
Test Case 11 - Add Multiple Interfaces for an IPv6 Router
Short name
dovetail.ipv6.tc011.router_add_multiple_interface
Use case specification
This test case evaluates the SUT ability of adding multiple interface
to a router, the reference is,
tempest.api.network.test_routers.RoutersIpV6Test.test_add_multiple_router_interfaces
Basic test flow execution description and pass/fail criteria
- Test action 1: Create 2 networks named network01 and network02 sequentially,
storing the “id” parameters returned in the response
- Test action 2: Create an IPv6 subnet01 in network01, an IPv6 subnet02 in network02 sequentially,
storing the “id” parameters returned in the response
- Test action 3: Create a router, storing the “id” parameter returned in the response
- Test action 4: Create interface01 with subnet01 and the router
- Test action 5: Verify the router_id stored in test action 3 equals to the interface01’s ‘device_id’
and subnet01_id stored in test action 2 equals to the interface01’s ‘subnet_id’
- Test assertion 1: the router_id equals to the interface01’s ‘device_id’
and subnet01_id equals to the interface01’s ‘subnet_id’
- Test action 5: Create interface02 with subnet02 and the router
- Test action 6: Verify the router_id stored in test action 3 equals to the interface02’s ‘device_id’
and subnet02_id stored in test action 2 equals to the interface02’s ‘subnet_id’
- Test assertion 2: the router_id equals to the interface02’s ‘device_id’
and subnet02_id equals to the interface02’s ‘subnet_id’
- Test action 7: Delete the interfaces, router, IPv6 subnets and networks, networks, subnets, then list
all interfaces, ports, IPv6 subnets, networks, the test passes if the deleted ones
are not found in the list.
- Test assertion 3: The interfaces, router, IPv6 subnets and networks ids are not present in the lists
after deleting
This test evaluates the ability to use bulk create commands to create networks, IPv6 subnets and ports on
the SUT API. Specifically it verifies that:
- Interface create commands to create interface with IPv6 subnet and router, interface ‘device_id’ and
‘subnet_id’ should equal to the router id and IPv6 subnet id, respectively.
- Interface create commands to create multiple interface with the same router and multiple IPv6 subnets.
- All items created using create commands are able to be removed using the returned identifiers
Post conditions
None
Test Case 12 - Add and Remove an IPv6 Router Interface with port_id
Short name
dovetail.ipv6.tc012.router_interface_add_remove_with_port
Use case specification
This test case evaluates the SUT abiltiy of adding, removing router interface to
a port, the subnet_id and port_id of the interface will be checked,
the port’s device_id will be checked if equals to the router_id or not. The
reference is,
tempest.api.network.test_routers.RoutersIpV6Test.test_add_remove_router_interface_with_port_id
Basic test flow execution description and pass/fail criteria
- Test action 1: Create a network, storing the “id” parameter returned in the response
- Test action 2: Create an IPv6 subnet of the network, storing the “id” parameter returned in the response
- Test action 3: Create a router, storing the “id” parameter returned in the response
- Test action 4: Create a port of the network, storing the “id” parameter returned in the response
- Test action 5: Add router interface to the port created, storing the “id” parameter returned in the response
- Test action 6: Verify the interface’s keys include ‘subnet_id’ and ‘port_id’
- Test assertion 1: the interface’s keys include ‘subnet_id’ and ‘port_id’
- Test action 7: Show the port details, verify the ‘device_id’ in port details equals to the router id stored
in test action 3
- Test assertion 2: ‘device_id’ in port details equals to the router id
- Test action 8: Delete the interface, port, router, subnet and network, then list
all interfaces, ports, routers, subnets and networks, the test passes if the deleted
ones are not found in the list.
- Test assertion 3: interfaces, ports, routers, subnets and networks are not found in the lists after deleting
This test evaluates the ability to use add/remove commands to add/remove router interface to the port,
show commands to show port details on the SUT API. Specifically it verifies that:
- Router_interface add commands to add router interface to a port, the interface’s keys should include ‘subnet_id’ and ‘port_id’
- Port show commands to show ‘device_id’ in port details, which should be equal to the router id
- All items created using create commands are able to be removed using the returned identifiers
Post conditions
None
Test Case 13 - Add and Remove an IPv6 Router Interface with subnet_id
Short name
dovetail.ipv6.tc013.router_interface_add_remove
Use case specification
This test case evaluates the SUT API ability of adding and removing a router interface with
the IPv6 subnet id, the reference is
tempest.api.network.test_routers.RoutersIpV6Test.test_add_remove_router_interface_with_subnet_id
Basic test flow execution description and pass/fail criteria
- Test action 1: Create a network, storing the “id” parameter returned in the response
- Test action 2: Create an IPv6 subnet with the network created, storing the “id” parameter
returned in the response
- Test action 3: Create a router, storing the “id” parameter returned in the response
- Test action 4: Add a router interface with the stored ids of the router and IPv6 subnet
- Test assertion 1: Key ‘subnet_id’ is included in the added interface’s keys
- Test assertion 2: Key ‘port_id’ is included in the added interface’s keys
- Test action 5: Show the port info with the stored interface’s port id
- Test assertion 3:: The stored router id is equal to the device id shown in the port info
- Test action 6: Delete the router interface created in test action 4, using the stored subnet id
- Test action 7: List all router interfaces, verifying the router interface is no longer present
- Test assertion 4: The router interface with the stored subnet id is not present
in the router interface list
- Test action 8: Delete the router created in test action 3, using the stored router id
- Test action 9: List all routers, verifying the router id is no longer present
- Test assertion 5: The router “id” parameter is not present in the router list
- Test action 10: Delete the subnet created in test action 2, using the stored subnet id
- Test action 11: List all subnets, verifying the subnet id is no longer present
- Test assertion 6: The subnet “id” parameter is not present in the subnet list
- Test action 12: Delete the network created in test action 1, using the stored network id
- Test action 13: List all networks, verifying the network id is no longer present
- Test assertion 7: The network “id” parameter is not present in the network list
This test evaluates the ability to add and remove router interface with the subnet id on the
SUT API. Specifically it verifies that:
- Router interface add command returns valid ‘subnet_id’ parameter which is reported
in the interface’s keys
- Router interface add command returns valid ‘port_id’ parameter which is reported
in the interface’s keys
- All items created using create commands are able to be removed using the returned identifiers
Post conditions
None
Test Case 14 - Create, Show, List, Update and Delete an IPv6 router
Short name
dovetail.ipv6.tc014.router_create_show_list_update_delete
Use case specification
This test case evaluates the SUT API ability of creating, showing, listing, updating
and deleting routers, the reference is
tempest.api.network.test_routers.RoutersIpV6Test.test_create_show_list_update_delete_router
Test preconditions
There should exist an OpenStack external network.
Basic test flow execution description and pass/fail criteria
- Test action 1: Create a router, set the admin_state_up to be False and external_network_id
to be public network id, storing the “id” parameter returned in the response
- Test assertion 1: The created router’s admin_state_up is False
- Test assertion 2: The created router’s external network id equals to the public network id
- Test action 2: Show details of the router created in test action 1, using the stored router id
- Test assertion 3: The router’s name shown is the same as the router created
- Test assertion 4: The router’s external network id shown is the same as the public network id
- Test action 3: List all routers and verify if created router is in response message
- Test assertion 5: The stored router id is in the router list
- Test action 4: Update the name of router and verify if it is updated
- Test assertion 6: The name of router equals to the name used to update in test action 4
- Test action 5: Show the details of router, using the stored router id
- Test assertion 7: The router’s name shown equals to the name used to update in test action 4
- Test action 6: Delete the router created in test action 1, using the stored router id
- Test action 7: List all routers, verifying the router id is no longer present
- Test assertion 8: The “id” parameter is not present in the router list
This test evaluates the ability to create, show, list, update and delete router on
the SUT API. Specifically it verifies that:
- Router create command returns valid “admin_state_up” and “id” parameters which equal to the
“admin_state_up” and “id” returned in the response
- Router show command returns valid “name” parameter which equals to the “name” returned in the response
- Router show command returns valid “external network id” parameters which equals to the public network id
- Router list command returns valid “id” parameter which equals to the stored router “id”
- Router update command returns updated “name” parameters which equals to the “name” used to update
- Router created using create command is able to be removed using the returned identifiers
Post conditions
None
Test Case 15 - Create, List, Update, Show and Delete an IPv6 security group
Short name
dovetail.ipv6.tc015.security_group_create_list_update_show_delete
Use case specification
This test case evaluates the SUT API ability of creating, listing, updating, showing
and deleting security groups, the reference is
tempest.api.network.test_security_groups.SecGroupIPv6Test.test_create_list_update_show_delete_security_group
Basic test flow execution description and pass/fail criteria
- Test action 1: Create a security group, storing the “id” parameter returned in the response
- Test action 2: List all security groups and verify if created security group is there in response
- Test assertion 1: The created security group’s “id” is found in the list
- Test action 3: Update the name and description of this security group, using the stored id
- Test action 4: Verify if the security group’s name and description are updated
- Test assertion 2: The security group’s name equals to the name used in test action 3
- Test assertion 3: The security group’s description equals to the description used in test action 3
- Test action 5: Show details of the updated security group, using the stored id
- Test assertion 4: The security group’s name shown equals to the name used in test action 3
- Test assertion 5: The security group’s description shown equals to the description used in test action 3
- Test action 6: Delete the security group created in test action 1, using the stored id
- Test action 7: List all security groups, verifying the security group’s id is no longer present
- Test assertion 6: The “id” parameter is not present in the security group list
This test evaluates the ability to create list, update, show and delete security group on
the SUT API. Specifically it verifies that:
- Security group create commands return valid “id” parameter which is reported in the list commands
- Security group update commands return valid “name” and “description” parameters which are
reported in the show commands
- Security group created using create command is able to be removed using the returned identifiers
Post conditions
None
Test Case 16 - Create, Show and Delete IPv6 security group rule
Short name
dovetail.ipv6.tc016.security_group_rule_create_show_delete
Use case specification
This test case evaluates the SUT API ability of creating, showing, listing and deleting
security group rules, the reference is
tempest.api.network.test_security_groups.SecGroupIPv6Test.test_create_show_delete_security_group_rule
Basic test flow execution description and pass/fail criteria
- Test action 1: Create a security group, storing the “id” parameter returned in the response
- Test action 2: Create a rule of the security group with protocol tcp, udp and icmp, respectively,
using the stored security group’s id, storing the “id” parameter returned in the response
- Test action 3: Show details of the created security group rule, using the stored id of the
security group rule
- Test assertion 1: All the created security group rule’s values equal to the rule values
shown in test action 3
- Test action 4: List all security group rules
- Test assertion 2: The stored security group rule’s id is found in the list
- Test action 5: Delete the security group rule, using the stored security group rule’s id
- Test action 6: List all security group rules, verifying the security group rule’s id is no longer present
- Test assertion 3: The security group rule “id” parameter is not present in the list
- Test action 7: Delete the security group, using the stored security group’s id
- Test action 8: List all security groups, verifying the security group’s id is no longer present
- Test assertion 4: The security group “id” parameter is not present in the list
This test evaluates the ability to create, show, list and delete security group rules on
the SUT API. Specifically it verifies that:
- Security group rule create command returns valid values which are reported in the show command
- Security group rule created using create command is able to be removed using the returned identifiers
Post conditions
None
Test Case 17 - List IPv6 Security Groups
Short name
dovetail.ipv6.tc017.security_group_list
Use case specification
This test case evaluates the SUT API ability of listing security groups, the reference is
tempest.api.network.test_security_groups.SecGroupIPv6Test.test_list_security_groups
Test preconditions
There should exist a default security group.
Basic test flow execution description and pass/fail criteria
- Test action 1: List all security groups
- Test action 2: Verify the default security group exists in the list, the test passes
if the default security group exists
- Test assertion 1: The default security group is in the list
This test evaluates the ability to list security groups on the SUT API.
Specifically it verifies that:
- Security group list command return valid security groups which include the default security group
Post conditions
None
Test Case 18 - IPv6 Address Assignment - Dual Stack, SLAAC, DHCPv6 Stateless
Short name
dovetail.ipv6.tc018.dhcpv6_stateless
Use case specification
This test case evaluates IPv6 address assignment in ipv6_ra_mode ‘dhcpv6_stateless’
and ipv6_address_mode ‘dhcpv6_stateless’.
In this case, guest instance obtains IPv6 address from OpenStack managed radvd
using SLAAC and optional info from dnsmasq using DHCPv6 stateless. This test case then
verifies the ping6 available VM can ping the other VM’s v4 and v6 addresses
as well as the v6 subnet’s gateway ip in the same network, the reference is
tempest.scenario.test_network_v6.TestGettingAddress.test_dhcp6_stateless_from_os
Test preconditions
There should exist a public router or a public network.
Basic test flow execution description and pass/fail criteria
- Test action 1: Create one network, storing the “id” parameter returned in the response
- Test action 2: Create one IPv4 subnet of the created network, storing the “id”
parameter returned in the response
- Test action 3: If there exists a public router, use it as the router. Otherwise,
use the public network to create a router
- Test action 4: Connect the IPv4 subnet to the router, using the stored IPv4 subnet id
- Test action 5: Create one IPv6 subnet of the network created in test action 1 in
ipv6_ra_mode ‘dhcpv6_stateless’ and ipv6_address_mode ‘dhcpv6_stateless’,
storing the “id” parameter returned in the response
- Test action 6: Connect the IPv6 subnet to the router, using the stored IPv6 subnet id
- Test action 7: Boot two VMs on this network, storing the “id” parameters returned in the response
- Test assertion 1: The vNIC of each VM gets one v4 address and one v6 address actually assigned
- Test assertion 2: Each VM can ping the other’s v4 private address
- Test assertion 3: The ping6 available VM can ping the other’s v6 address
as well as the v6 subnet’s gateway ip
- Test action 8: Delete the 2 VMs created in test action 7, using the stored ids
- Test action 9: List all VMs, verifying the ids are no longer present
- Test assertion 4: The two “id” parameters are not present in the VM list
- Test action 10: Delete the IPv4 subnet created in test action 2, using the stored id
- Test action 11: Delete the IPv6 subnet created in test action 5, using the stored id
- Test action 12: List all subnets, verifying the ids are no longer present
- Test assertion 5: The “id” parameters of IPv4 and IPv6 are not present in the list
- Test action 13: Delete the network created in test action 1, using the stored id
- Test action 14: List all networks, verifying the id is no longer present
- Test assertion 6: The “id” parameter is not present in the network list
This test evaluates the ability to assign IPv6 addresses in ipv6_ra_mode
‘dhcpv6_stateless’ and ipv6_address_mode ‘dhcpv6_stateless’,
and verify the ping6 available VM can ping the other VM’s v4 and v6 addresses as well as
the v6 subnet’s gateway ip in the same network. Specifically it verifies that:
- The IPv6 addresses in mode ‘dhcpv6_stateless’ assigned successfully
- The VM can ping the other VM’s IPv4 and IPv6 private addresses as well as the v6 subnet’s gateway ip
- All items created using create commands are able to be removed using the returned identifiers
Post conditions
None
Test Case 19 - IPv6 Address Assignment - Dual Net, Dual Stack, SLAAC, DHCPv6 Stateless
Short name
dovetail.ipv6.tc019.dualnet_dhcpv6_stateless
Use case specification
This test case evaluates IPv6 address assignment in ipv6_ra_mode ‘dhcpv6_stateless’
and ipv6_address_mode ‘dhcpv6_stateless’.
In this case, guest instance obtains IPv6 address from OpenStack managed radvd
using SLAAC and optional info from dnsmasq using DHCPv6 stateless. This test case then
verifies the ping6 available VM can ping the other VM’s v4 address in one network
and v6 address in another network as well as the v6 subnet’s gateway ip, the reference is
tempest.scenario.test_network_v6.TestGettingAddress.test_dualnet_dhcp6_stateless_from_os
Test preconditions
There should exists a public router or a public network.
Basic test flow execution description and pass/fail criteria
- Test action 1: Create one network, storing the “id” parameter returned in the response
- Test action 2: Create one IPv4 subnet of the created network, storing the “id”
parameter returned in the response
- Test action 3: If there exists a public router, use it as the router. Otherwise,
use the public network to create a router
- Test action 4: Connect the IPv4 subnet to the router, using the stored IPv4 subnet id
- Test action 5: Create another network, storing the “id” parameter returned in the response
- Test action 6: Create one IPv6 subnet of network created in test action 5 in
ipv6_ra_mode ‘dhcpv6_stateless’ and ipv6_address_mode ‘dhcpv6_stateless’,
storing the “id” parameter returned in the response
- Test action 7: Connect the IPv6 subnet to the router, using the stored IPv6 subnet id
- Test action 8: Boot two VMs on these two networks, storing the “id” parameters returned in the response
- Test action 9: Turn on 2nd NIC of each VM for the network created in test action 5
- Test assertion 1: The 1st vNIC of each VM gets one v4 address assigned and
the 2nd vNIC of each VM gets one v6 address actually assigned
- Test assertion 2: Each VM can ping the other’s v4 private address
- Test assertion 3: The ping6 available VM can ping the other’s v6 address
as well as the v6 subnet’s gateway ip
- Test action 10: Delete the 2 VMs created in test action 8, using the stored ids
- Test action 11: List all VMs, verifying the ids are no longer present
- Test assertion 4: The two “id” parameters are not present in the VM list
- Test action 12: Delete the IPv4 subnet created in test action 2, using the stored id
- Test action 13: Delete the IPv6 subnet created in test action 6, using the stored id
- Test action 14: List all subnets, verifying the ids are no longer present
- Test assertion 5: The “id” parameters of IPv4 and IPv6 are not present in the list
- Test action 15: Delete the 2 networks created in test action 1 and 5, using the stored ids
- Test action 16: List all networks, verifying the ids are no longer present
- Test assertion 6: The two “id” parameters are not present in the network list
This test evaluates the ability to assign IPv6 addresses in ipv6_ra_mode ‘dhcpv6_stateless’
and ipv6_address_mode ‘dhcpv6_stateless’, and verify the ping6 available VM can ping
the other VM’s v4 address in one network and v6 address in another network as well as
the v6 subnet’s gateway ip. Specifically it verifies that:
- The IPv6 addresses in mode ‘dhcpv6_stateless’ assigned successfully
- The VM can ping the other VM’s IPv4 address in one network and IPv6 address in another
network as well as the v6 subnet’s gateway ip
- All items created using create commands are able to be removed using the returned identifiers
Post conditions
None
Test Case 20 - IPv6 Address Assignment - Multiple Prefixes, Dual Stack, SLAAC, DHCPv6 Stateless
Short name
dovetail.ipv6.tc020.multiple_prefixes_dhcpv6_stateless
Use case specification
This test case evaluates IPv6 address assignment in ipv6_ra_mode ‘dhcpv6_stateless’
and ipv6_address_mode ‘dhcpv6_stateless’.
In this case, guest instance obtains IPv6 addresses from OpenStack managed radvd
using SLAAC and optional info from dnsmasq using DHCPv6 stateless. This test case then
verifies the ping6 available VM can ping the other VM’s one v4 address and two v6
addresses with different prefixes as well as the v6 subnets’ gateway ips in the
same network, the reference is
tempest.scenario.test_network_v6.TestGettingAddress.test_multi_prefix_dhcpv6_stateless
Test preconditions
There should exist a public router or a public network.
Basic test flow execution description and pass/fail criteria
- Test action 1: Create one network, storing the “id” parameter returned in the response
- Test action 2: Create one IPv4 subnet of the created network, storing the “id”
parameter returned in the response
- Test action 3: If there exists a public router, use it as the router. Otherwise,
use the public network to create a router
- Test action 4: Connect the IPv4 subnet to the router, using the stored IPv4 subnet id
- Test action 5: Create two IPv6 subnets of the network created in test action 1 in
ipv6_ra_mode ‘dhcpv6_stateless’ and ipv6_address_mode ‘dhcpv6_stateless’,
storing the “id” parameters returned in the response
- Test action 6: Connect the two IPv6 subnets to the router, using the stored IPv6 subnet ids
- Test action 7: Boot two VMs on this network, storing the “id” parameters returned in the response
- Test assertion 1: The vNIC of each VM gets one v4 address and two v6 addresses with
different prefixes actually assigned
- Test assertion 2: Each VM can ping the other’s v4 private address
- Test assertion 3: The ping6 available VM can ping the other’s v6 addresses
as well as the v6 subnets’ gateway ips
- Test action 8: Delete the 2 VMs created in test action 7, using the stored ids
- Test action 9: List all VMs, verifying the ids are no longer present
- Test assertion 4: The two “id” parameters are not present in the VM list
- Test action 10: Delete the IPv4 subnet created in test action 2, using the stored id
- Test action 11: Delete two IPv6 subnets created in test action 5, using the stored ids
- Test action 12: List all subnets, verifying the ids are no longer present
- Test assertion 5: The “id” parameters of IPv4 and IPv6 are not present in the list
- Test action 13: Delete the network created in test action 1, using the stored id
- Test action 14: List all networks, verifying the id is no longer present
- Test assertion 6: The “id” parameter is not present in the network list
This test evaluates the ability to assign IPv6 addresses in ipv6_ra_mode ‘dhcpv6_stateless’
and ipv6_address_mode ‘dhcpv6_stateless’,
and verify the ping6 available VM can ping the other VM’s v4 address and two
v6 addresses with different prefixes as well as the v6 subnets’ gateway ips in the same network.
Specifically it verifies that:
- The different prefixes IPv6 addresses in mode ‘dhcpv6_stateless’ assigned successfully
- The VM can ping the other VM’s IPv4 and IPv6 private addresses as well as the v6 subnets’ gateway ips
- All items created using create commands are able to be removed using the returned identifiers
Post conditions
None
Test Case 21 - IPv6 Address Assignment - Dual Net, Multiple Prefixes, Dual Stack, SLAAC, DHCPv6 Stateless
Short name
dovetail.ipv6.tc021.dualnet_multiple_prefixes_dhcpv6_stateless
Use case specification
This test case evaluates IPv6 address assignment in ipv6_ra_mode ‘dhcpv6_stateless’
and ipv6_address_mode ‘dhcpv6_stateless’.
In this case, guest instance obtains IPv6 addresses from OpenStack managed radvd
using SLAAC and optional info from dnsmasq using DHCPv6 stateless. This test case then
verifies the ping6 available VM can ping the other VM’s v4 address in one network
and two v6 addresses with different prefixes in another network as well as the
v6 subnets’ gateway ips, the reference is
tempest.scenario.test_network_v6.TestGettingAddress.test_dualnet_multi_prefix_dhcpv6_stateless
Test preconditions
There should exist a public router or a public network.
Basic test flow execution description and pass/fail criteria
- Test action 1: Create one network, storing the “id” parameter returned in the response
- Test action 2: Create one IPv4 subnet of the created network, storing the “id”
parameter returned in the response
- Test action 3: If there exists a public router, use it as the router. Otherwise,
use the public network to create a router
- Test action 4: Connect the IPv4 subnet to the router, using the stored IPv4 subnet id
- Test action 5: Create another network, storing the “id” parameter returned in the response
- Test action 6: Create two IPv6 subnets of network created in test action 5 in
ipv6_ra_mode ‘dhcpv6_stateless’ and ipv6_address_mode ‘dhcpv6_stateless’,
storing the “id” parameters returned in the response
- Test action 7: Connect the two IPv6 subnets to the router, using the stored IPv6 subnet ids
- Test action 8: Boot two VMs on these two networks, storing the “id” parameters returned in the response
- Test action 9: Turn on 2nd NIC of each VM for the network created in test action 5
- Test assertion 1: The vNIC of each VM gets one v4 address and two v6 addresses
with different prefixes actually assigned
- Test assertion 2: Each VM can ping the other’s v4 private address
- Test assertion 3: The ping6 available VM can ping the other’s v6 addresses
as well as the v6 subnets’ gateway ips
- Test action 10: Delete the 2 VMs created in test action 8, using the stored ids
- Test action 11: List all VMs, verifying the ids are no longer present
- Test assertion 4: The two “id” parameters are not present in the VM list
- Test action 12: Delete the IPv4 subnet created in test action 2, using the stored id
- Test action 13: Delete two IPv6 subnets created in test action 6, using the stored ids
- Test action 14: List all subnets, verifying the ids are no longer present
- Test assertion 5: The “id” parameters of IPv4 and IPv6 are not present in the list
- Test action 15: Delete the 2 networks created in test action 1 and 5, using the stored ids
- Test action 16: List all networks, verifying the ids are no longer present
- Test assertion 6: The two “id” parameters are not present in the network list
This test evaluates the ability to assign IPv6 addresses in ipv6_ra_mode ‘dhcpv6_stateless’
and ipv6_address_mode ‘dhcpv6_stateless’,
and verify the ping6 available VM can ping the other VM’s v4 address in one network and two
v6 addresses with different prefixes in another network as well as the v6 subnets’
gateway ips. Specifically it verifies that:
- The IPv6 addresses in mode ‘dhcpv6_stateless’ assigned successfully
- The VM can ping the other VM’s IPv4 and IPv6 private addresses as well as the v6 subnets’ gateway ips
- All items created using create commands are able to be removed using the returned identifiers
Post conditions
None
Test Case 22 - IPv6 Address Assignment - Dual Stack, SLAAC
Short name
dovetail.ipv6.tc022.slaac
Use case specification
This test case evaluates IPv6 address assignment in ipv6_ra_mode ‘slaac’ and
ipv6_address_mode ‘slaac’.
In this case, guest instance obtains IPv6 address from OpenStack managed radvd
using SLAAC. This test case then verifies the ping6 available VM can ping the other
VM’s v4 and v6 addresses as well as the v6 subnet’s gateway ip in the
same network, the reference is
tempest.scenario.test_network_v6.TestGettingAddress.test_slaac_from_os
Test preconditions
There should exist a public router or a public network.
Basic test flow execution description and pass/fail criteria
- Test action 1: Create one network, storing the “id” parameter returned in the response
- Test action 2: Create one IPv4 subnet of the created network, storing the “id”
parameter returned in the response
- Test action 3: If there exists a public router, use it as the router. Otherwise,
use the public network to create a router
- Test action 4: Connect the IPv4 subnet to the router, using the stored IPv4 subnet id
- Test action 5: Create one IPv6 subnet of the network created in test action 1 in
ipv6_ra_mode ‘slaac’ and ipv6_address_mode ‘slaac’, storing the “id” parameter returned in the response
- Test action 6: Connect the IPv6 subnet to the router, using the stored IPv6 subnet id
- Test action 7: Boot two VMs on this network, storing the “id” parameters returned in the response
- Test assertion 1: The vNIC of each VM gets one v4 address and one v6 address actually assigned
- Test assertion 2: Each VM can ping the other’s v4 private address
- Test assertion 3: The ping6 available VM can ping the other’s v6 address
as well as the v6 subnet’s gateway ip
- Test action 8: Delete the 2 VMs created in test action 7, using the stored ids
- Test action 9: List all VMs, verifying the ids are no longer present
- Test assertion 4: The two “id” parameters are not present in the VM list
- Test action 10: Delete the IPv4 subnet created in test action 2, using the stored id
- Test action 11: Delete the IPv6 subnet created in test action 5, using the stored id
- Test action 12: List all subnets, verifying the ids are no longer present
- Test assertion 5: The “id” parameters of IPv4 and IPv6 are not present in the list
- Test action 13: Delete the network created in test action 1, using the stored id
- Test action 14: List all networks, verifying the id is no longer present
- Test assertion 6: The “id” parameter is not present in the network list
This test evaluates the ability to assign IPv6 addresses in ipv6_ra_mode ‘slaac’
and ipv6_address_mode ‘slaac’,
and verify the ping6 available VM can ping the other VM’s v4 and v6 addresses as well as
the v6 subnet’s gateway ip in the same network. Specifically it verifies that:
- The IPv6 addresses in mode ‘slaac’ assigned successfully
- The VM can ping the other VM’s IPv4 and IPv6 private addresses as well as the v6 subnet’s gateway ip
- All items created using create commands are able to be removed using the returned identifiers
Post conditions
None
Test Case 23 - IPv6 Address Assignment - Dual Net, Dual Stack, SLAAC
Short name
dovetail.ipv6.tc023.dualnet_slaac
Use case specification
This test case evaluates IPv6 address assignment in ipv6_ra_mode ‘slaac’ and
ipv6_address_mode ‘slaac’.
In this case, guest instance obtains IPv6 address from OpenStack managed radvd
using SLAAC. This test case then verifies the ping6 available VM can ping the other
VM’s v4 address in one network and v6 address in another network as well as the
v6 subnet’s gateway ip, the reference is
tempest.scenario.test_network_v6.TestGettingAddress.test_dualnet_slaac_from_os
Test preconditions
There should exist a public router or a public network.
Basic test flow execution description and pass/fail criteria
- Test action 1: Create one network, storing the “id” parameter returned in the response
- Test action 2: Create one IPv4 subnet of the created network, storing the “id”
parameter returned in the response
- Test action 3: If there exists a public router, use it as the router. Otherwise,
use the public network to create a router
- Test action 4: Connect the IPv4 subnet to the router, using the stored IPv4 subnet id
- Test action 5: Create another network, storing the “id” parameter returned in the response
- Test action 6: Create one IPv6 subnet of network created in test action 5 in
ipv6_ra_mode ‘slaac’ and ipv6_address_mode ‘slaac’, storing the “id” parameter returned in the response
- Test action 7: Connect the IPv6 subnet to the router, using the stored IPv6 subnet id
- Test action 8: Boot two VMs on these two networks, storing the “id” parameters returned in the response
- Test action 9: Turn on 2nd NIC of each VM for the network created in test action 5
- Test assertion 1: The 1st vNIC of each VM gets one v4 address assigned and
the 2nd vNIC of each VM gets one v6 address actually assigned
- Test assertion 2: Each VM can ping the other’s v4 private address
- Test assertion 3: The ping6 available VM can ping the other’s v6 address
as well as the v6 subnet’s gateway ip
- Test action 10: Delete the 2 VMs created in test action 8, using the stored ids
- Test action 11: List all VMs, verifying the ids are no longer present
- Test assertion 4: The two “id” parameters are not present in the VM list
- Test action 12: Delete the IPv4 subnet created in test action 2, using the stored id
- Test action 13: Delete the IPv6 subnet created in test action 6, using the stored id
- Test action 14: List all subnets, verifying the ids are no longer present
- Test assertion 5: The “id” parameters of IPv4 and IPv6 are not present in the list
- Test action 15: Delete the 2 networks created in test action 1 and 5, using the stored ids
- Test action 16: List all networks, verifying the ids are no longer present
- Test assertion 6: The two “id” parameters are not present in the network list
This test evaluates the ability to assign IPv6 addresses in ipv6_ra_mode ‘slaac’
and ipv6_address_mode ‘slaac’,
and verify the ping6 available VM can ping the other VM’s v4 address in one network and
v6 address in another network as well as the v6 subnet’s gateway ip. Specifically it verifies that:
- The IPv6 addresses in mode ‘slaac’ assigned successfully
- The VM can ping the other VM’s IPv4 address in one network and IPv6 address
in another network as well as the v6 subnet’s gateway ip
- All items created using create commands are able to be removed using the returned identifiers
Post conditions
None
Test Case 24 - IPv6 Address Assignment - Multiple Prefixes, Dual Stack, SLAAC
Short name
dovetail.ipv6.tc024.multiple_prefixes_slaac
Use case specification
This test case evaluates IPv6 address assignment in ipv6_ra_mode ‘slaac’ and
ipv6_address_mode ‘slaac’.
In this case, guest instance obtains IPv6 addresses from OpenStack managed radvd
using SLAAC. This test case then verifies the ping6 available VM can ping the other
VM’s one v4 address and two v6 addresses with different prefixes as well as the v6
subnets’ gateway ips in the same network, the reference is
tempest.scenario.test_network_v6.TestGettingAddress.test_multi_prefix_slaac
Test preconditions
There should exists a public router or a public network.
Basic test flow execution description and pass/fail criteria
- Test action 1: Create one network, storing the “id” parameter returned in the response
- Test action 2: Create one IPv4 subnet of the created network, storing the “id
parameter returned in the response
- Test action 3: If there exists a public router, use it as the router. Otherwise,
use the public network to create a router
- Test action 4: Connect the IPv4 subnet to the router, using the stored IPv4 subnet id
- Test action 5: Create two IPv6 subnets of the network created in test action 1 in
ipv6_ra_mode ‘slaac’ and ipv6_address_mode ‘slaac’, storing the “id” parameters returned in the response
- Test action 6: Connect the two IPv6 subnets to the router, using the stored IPv6 subnet ids
- Test action 7: Boot two VMs on this network, storing the “id” parameters returned in the response
- Test assertion 1: The vNIC of each VM gets one v4 address and two v6 addresses with
different prefixes actually assigned
- Test assertion 2: Each VM can ping the other’s v4 private address
- Test assertion 3: The ping6 available VM can ping the other’s v6 addresses
as well as the v6 subnets’ gateway ips
- Test action 8: Delete the 2 VMs created in test action 7, using the stored ids
- Test action 9: List all VMs, verifying the ids are no longer present
- Test assertion 4: The two “id” parameters are not present in the VM list
- Test action 10: Delete the IPv4 subnet created in test action 2, using the stored id
- Test action 11: Delete two IPv6 subnets created in test action 5, using the stored ids
- Test action 12: List all subnets, verifying the ids are no longer present
- Test assertion 5: The “id” parameters of IPv4 and IPv6 are not present in the list
- Test action 13: Delete the network created in test action 1, using the stored id
- Test action 14: List all networks, verifying the id is no longer present
- Test assertion 6: The “id” parameter is not present in the network list
This test evaluates the ability to assign IPv6 addresses in ipv6_ra_mode ‘slaac’
and ipv6_address_mode ‘slaac’,
and verify the ping6 available VM can ping the other VM’s v4 address and two
v6 addresses with different prefixes as well as the v6 subnets’ gateway ips in the same network.
Specifically it verifies that:
- The different prefixes IPv6 addresses in mode ‘slaac’ assigned successfully
- The VM can ping the other VM’s IPv4 and IPv6 private addresses as well as the v6 subnets’ gateway ips
- All items created using create commands are able to be removed using the returned identifiers
Post conditions
None
Test Case 25 - IPv6 Address Assignment - Dual Net, Dual Stack, Multiple Prefixes, SLAAC
Short name
dovetail.ipv6.tc025.dualnet_multiple_prefixes_slaac
Use case specification
This test case evaluates IPv6 address assignment in ipv6_ra_mode ‘slaac’ and
ipv6_address_mode ‘slaac’.
In this case, guest instance obtains IPv6 addresses from OpenStack managed radvd
using SLAAC. This test case then verifies the ping6 available VM can ping the other
VM’s v4 address in one network and two v6 addresses with different prefixes in another
network as well as the v6 subnets’ gateway ips, the reference is
tempest.scenario.test_network_v6.TestGettingAddress.test_dualnet_multi_prefix_slaac
Test preconditions
There should exist a public router or a public network.
Basic test flow execution description and pass/fail criteria
- Test action 1: Create one network, storing the “id” parameter returned in the response
- Test action 2: Create one IPv4 subnet of the created network, storing the “id”
parameter returned in the response
- Test action 3: If there exists a public router, use it as the router. Otherwise,
use the public network to create a router
- Test action 4: Connect the IPv4 subnet to the router, using the stored IPv4 subnet id
- Test action 5: Create another network, storing the “id” parameter returned in the response
- Test action 6: Create two IPv6 subnets of network created in test action 5 in
ipv6_ra_mode ‘slaac’ and ipv6_address_mode ‘slaac’, storing the “id” parameters returned in the response
- Test action 7: Connect the two IPv6 subnets to the router, using the stored IPv6 subnet ids
- Test action 8: Boot two VMs on these two networks, storing the “id” parameters returned in the response
- Test action 9: Turn on 2nd NIC of each VM for the network created in test action 5
- Test assertion 1: The vNIC of each VM gets one v4 address and two v6 addresses
with different prefixes actually assigned
- Test assertion 2: Each VM can ping the other’s v4 private address
- Test assertion 3: The ping6 available VM can ping the other’s v6 addresses
as well as the v6 subnets’ gateway ips
- Test action 10: Delete the 2 VMs created in test action 8, using the stored ids
- Test action 11: List all VMs, verifying the ids are no longer present
- Test assertion 4: The two “id” parameters are not present in the VM list
- Test action 12: Delete the IPv4 subnet created in test action 2, using the stored id
- Test action 13: Delete two IPv6 subnets created in test action 6, using the stored ids
- Test action 14: List all subnets, verifying the ids are no longer present
- Test assertion 5: The “id” parameters of IPv4 and IPv6 are not present in the list
- Test action 15: Delete the 2 networks created in test action 1 and 5, using the stored ids
- Test action 16: List all networks, verifying the ids are no longer present
- Test assertion 6: The two “id” parameters are not present in the network list
This test evaluates the ability to assign IPv6 addresses in ipv6_ra_mode ‘slaac’
and ipv6_address_mode ‘slaac’,
and verify the ping6 available VM can ping the other VM’s v4 address in one network and two
v6 addresses with different prefixes in another network as well as the v6 subnets’ gateway ips.
Specifically it verifies that:
- The IPv6 addresses in mode ‘slaac’ assigned successfully
- The VM can ping the other VM’s IPv4 and IPv6 private addresses as well as the v6 subnets’ gateway ips
- All items created using create commands are able to be removed using the returned identifiers



















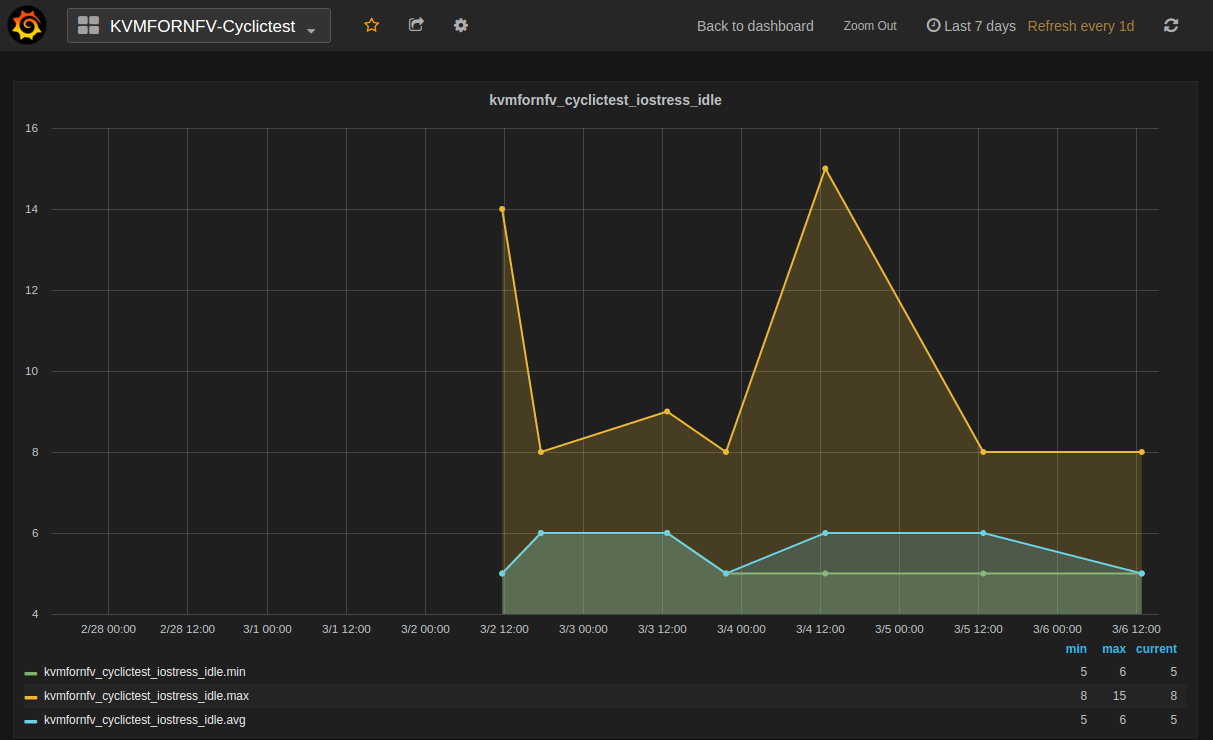
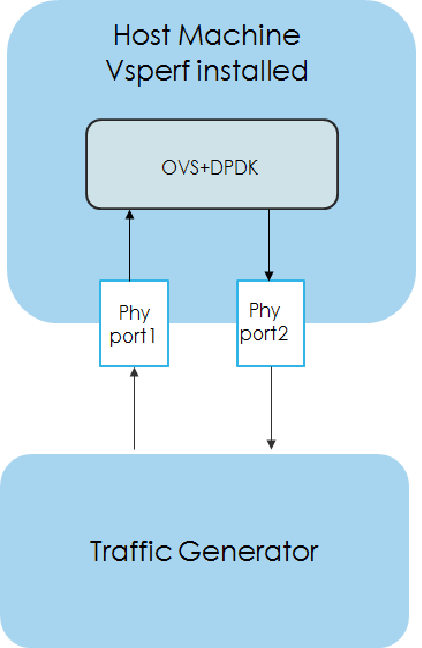
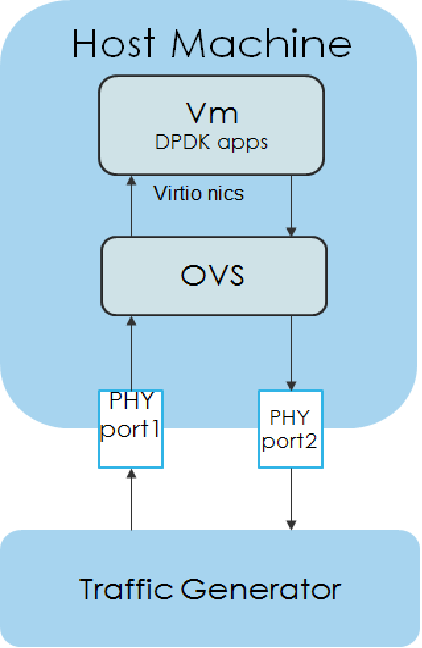
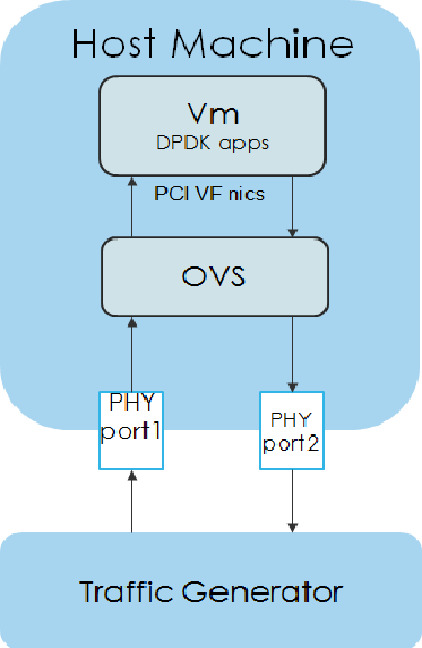
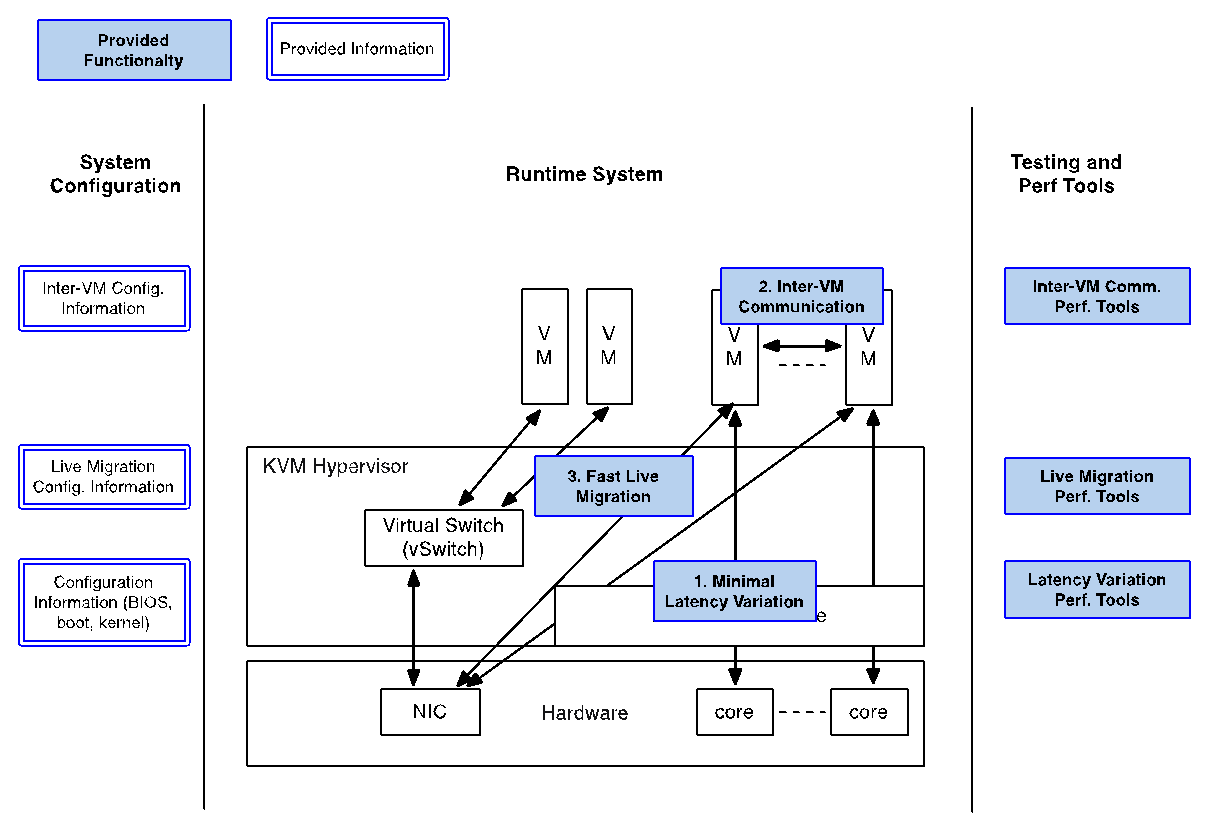


{kind=link}
{kind=link}