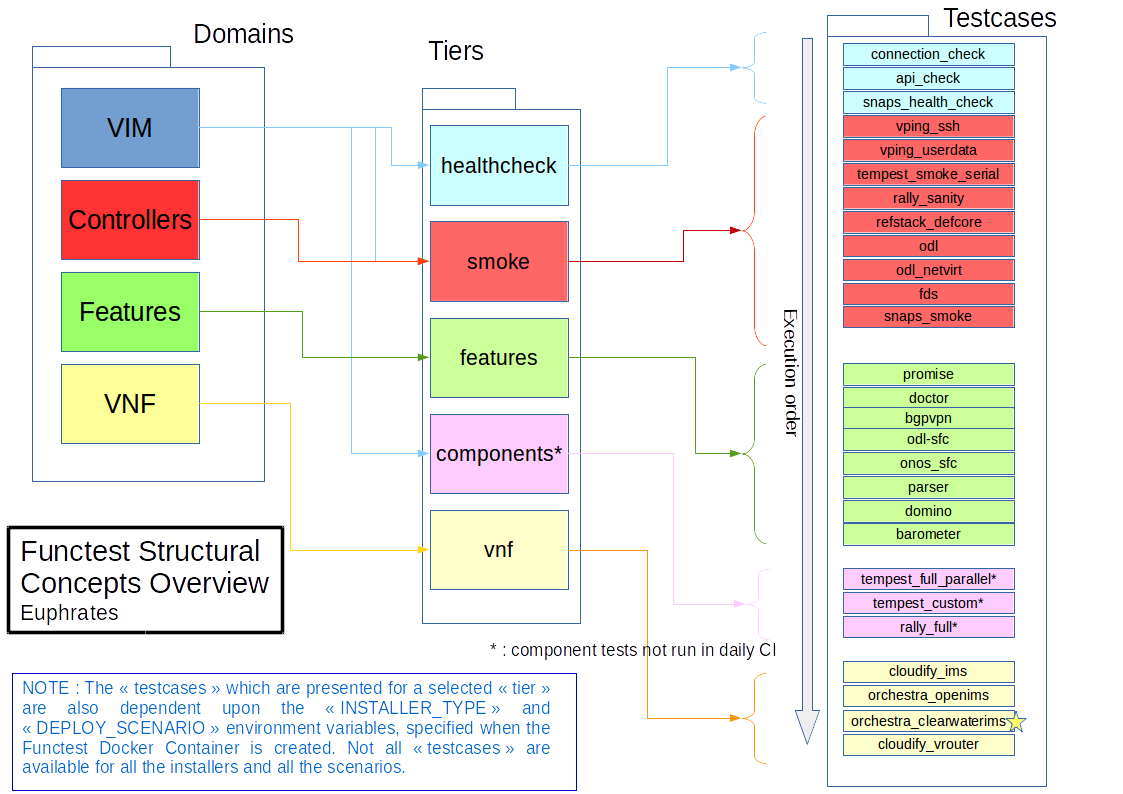
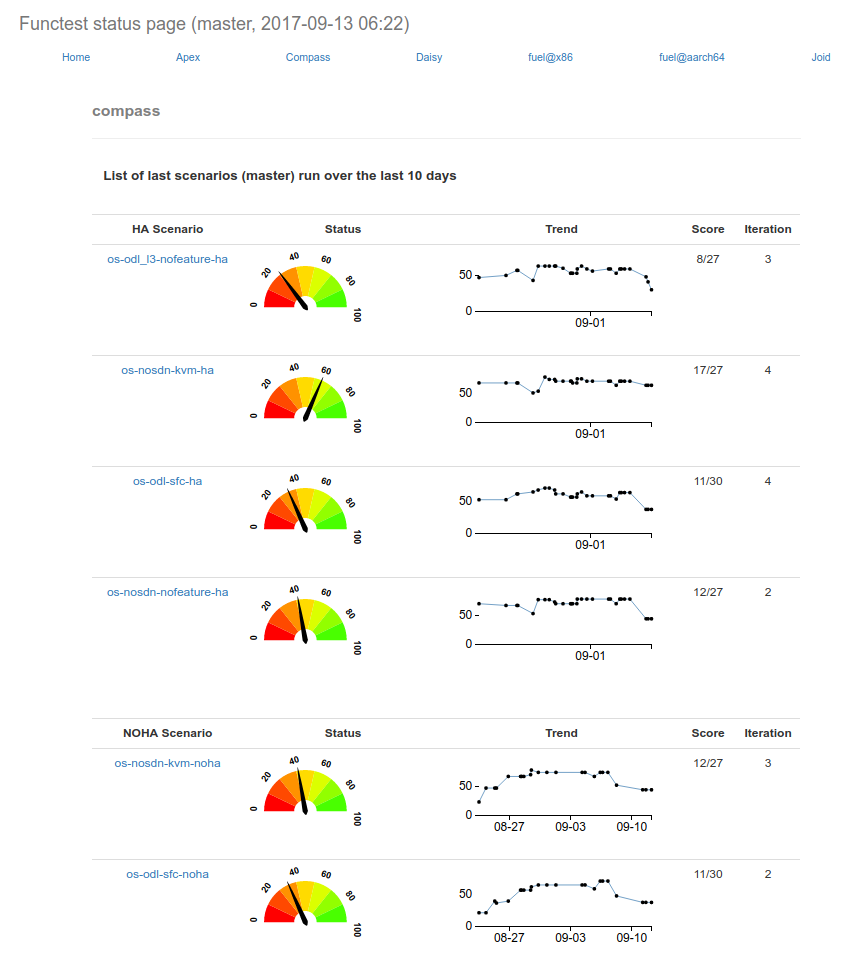
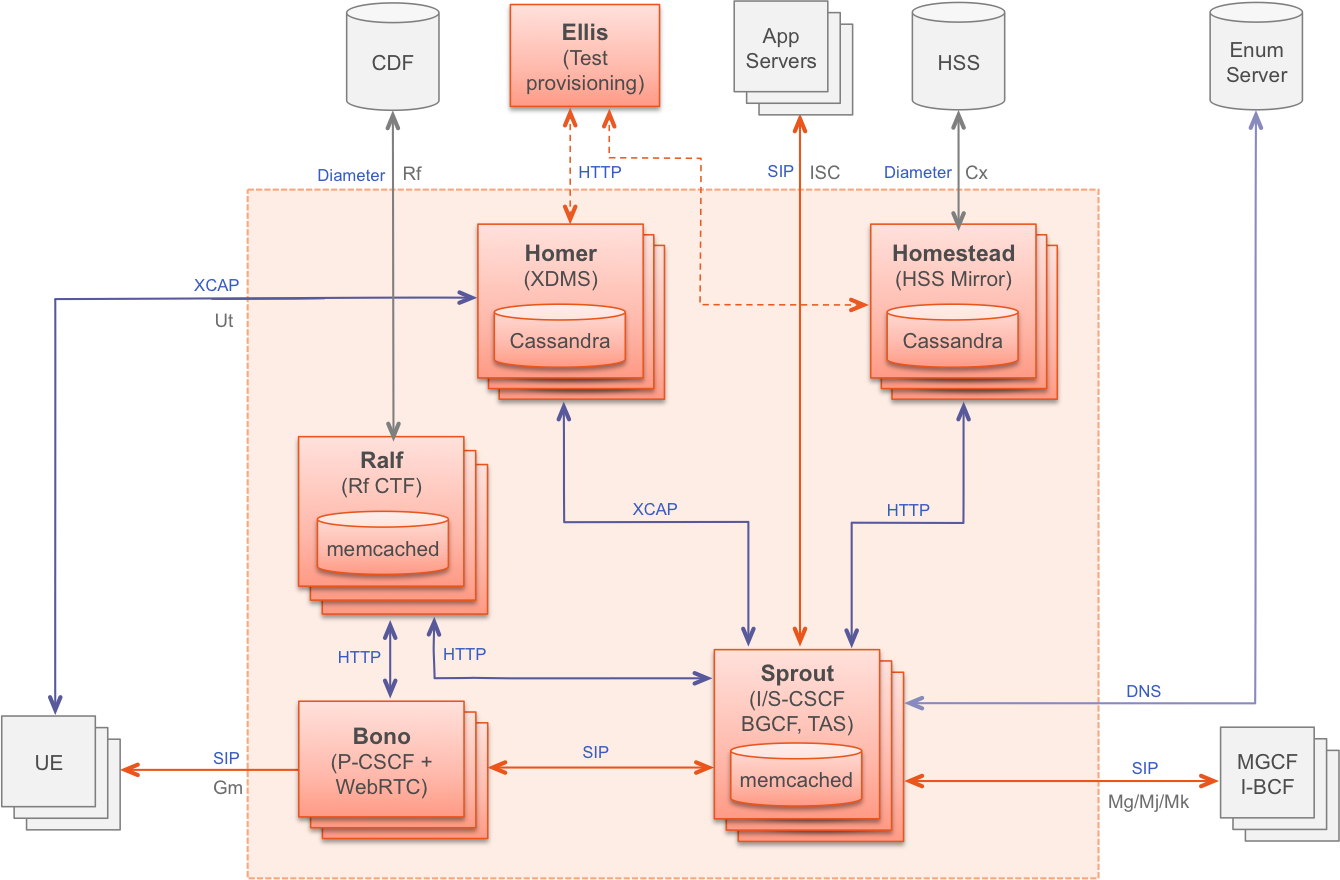
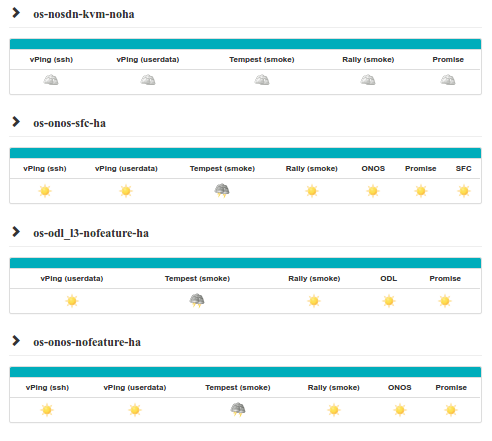
1. vSwitchPerf test suites userguide
1.1. General
VSPERF requires a traffic generators to run tests, automated traffic gen
support in VSPERF includes:
- IXIA traffic generator (IxNetwork hardware) and a machine that runs the IXIA
client software.
- Spirent traffic generator (TestCenter hardware chassis or TestCenter virtual
in a VM) and a VM to run the Spirent Virtual Deployment Service image,
formerly known as “Spirent LabServer”.
- Xena Network traffic generator (Xena hardware chassis) that houses the Xena
Traffic generator modules.
- Moongen software traffic generator. Requires a separate machine running
moongen to execute packet generation.
- T-Rex software traffic generator. Requires a separate machine running T-Rex
Server to execute packet generation.
If you want to use another traffic generator, please select the Dummy
generator.
1.2. VSPERF Installation
To see the supported Operating Systems, vSwitches and system requirements,
please follow the installation instructions <vsperf-installation>.
1.3. Traffic Generator Setup
Follow the Traffic generator instructions <trafficgen-installation> to
install and configure a suitable traffic generator.
1.4. Cloning and building src dependencies
In order to run VSPERF, you will need to download DPDK and OVS. You can
do this manually and build them in a preferred location, OR you could
use vswitchperf/src. The vswitchperf/src directory contains makefiles
that will allow you to clone and build the libraries that VSPERF depends
on, such as DPDK and OVS. To clone and build simply:
VSPERF can be used with stock OVS (without DPDK support). When build
is finished, the libraries are stored in src_vanilla directory.
The ‘make’ builds all options in src:
- Vanilla OVS
- OVS with vhost_user as the guest access method (with DPDK support)
The vhost_user build will reside in src/ovs/
The Vanilla OVS build will reside in vswitchperf/src_vanilla
To delete a src subdirectory and its contents to allow you to re-clone simply
use:
1.6. Using a custom settings file
If your 10_custom.conf doesn’t reside in the ./conf directory
of if you want to use an alternative configuration file, the file can
be passed to vsperf via the --conf-file argument.
$ ./vsperf --conf-file <path_to_custom_conf> ...
Note that configuration passed in via the environment (--load-env)
or via another command line argument will override both the default and
your custom configuration files. This “priority hierarchy” can be
described like so (1 = max priority):
- Testcase definition section
Parameters
- Command line arguments
- Environment variables
- Configuration file(s)
Further details about configuration files evaluation and special behaviour
of options with GUEST_ prefix could be found at design document.
1.7. Referencing parameter values
It is possible to use a special macro #PARAM() to refer to the value of
another configuration parameter. This reference is evaluated during
access of the parameter value (by settings.getValue() call), so it
can refer to parameters created during VSPERF runtime, e.g. NICS dictionary.
It can be used to reflect DUT HW details in the testcase definition.
Example:
{
...
"Name": "testcase",
"Parameters" : {
"TRAFFIC" : {
'l2': {
# set destination MAC to the MAC of the first
# interface from WHITELIST_NICS list
'dstmac' : '#PARAM(NICS[0]["mac"])',
},
},
...
1.8. Overriding values defined in configuration files
The configuration items can be overridden by command line argument
--test-params. In this case, the configuration items and
their values should be passed in form of item=value and separated
by semicolon.
Example:
$ ./vsperf --test-params "TRAFFICGEN_DURATION=10;TRAFFICGEN_PKT_SIZES=(128,);" \
"GUEST_LOOPBACK=['testpmd','l2fwd']" pvvp_tput
The second option is to override configuration items by Parameters section
of the test case definition. The configuration items can be added into Parameters
dictionary with their new values. These values will override values defined in
configuration files or specified by --test-params command line argument.
Example:
"Parameters" : {'TRAFFICGEN_PKT_SIZES' : (128,),
'TRAFFICGEN_DURATION' : 10,
'GUEST_LOOPBACK' : ['testpmd','l2fwd'],
}
NOTE: In both cases, configuration item names and their values must be specified
in the same form as they are defined inside configuration files. Parameter names
must be specified in uppercase and data types of original and new value must match.
Python syntax rules related to data types and structures must be followed.
For example, parameter TRAFFICGEN_PKT_SIZES above is defined as a tuple
with a single value 128. In this case trailing comma is mandatory, otherwise
value can be wrongly interpreted as a number instead of a tuple and vsperf
execution would fail. Please check configuration files for default values and their
types and use them as a basis for any customized values. In case of any doubt, please
check official python documentation related to data structures like tuples, lists
and dictionaries.
NOTE: Vsperf execution will terminate with runtime error in case, that unknown
parameter name is passed via --test-params CLI argument or defined in Parameters
section of test case definition. It is also forbidden to redefine a value of
TEST_PARAMS configuration item via CLI or Parameters section.
1.9. vloop_vnf
VSPERF uses a VM image called vloop_vnf for looping traffic in the deployment
scenarios involving VMs. The image can be downloaded from
http://artifacts.opnfv.org/.
Please see the installation instructions for information on vloop-vnf
images.
1.10. l2fwd Kernel Module
A Kernel Module that provides OSI Layer 2 Ipv4 termination or forwarding with
support for Destination Network Address Translation (DNAT) for both the MAC and
IP addresses. l2fwd can be found in <vswitchperf_dir>/src/l2fwd
1.11. Executing tests
All examples inside these docs assume, that user is inside the VSPERF
directory. VSPERF can be executed from any directory.
Before running any tests make sure you have root permissions by adding
the following line to /etc/sudoers:
username ALL=(ALL) NOPASSWD: ALL
username in the example above should be replaced with a real username.
To list the available tests:
To run a single test:
Where $TESTNAME is the name of the vsperf test you would like to run.
To run a group of tests, for example all tests with a name containing
‘RFC2544’:
$ ./vsperf --conf-file=<path_to_custom_conf>/10_custom.conf --tests="RFC2544"
To run all tests:
$ ./vsperf --conf-file=<path_to_custom_conf>/10_custom.conf
Some tests allow for configurable parameters, including test duration
(in seconds) as well as packet sizes (in bytes).
$ ./vsperf --conf-file user_settings.py \
--tests RFC2544Tput \
--test-params "TRAFFICGEN_DURATION=10;TRAFFICGEN_PKT_SIZES=(128,)"
For all available options, check out the help dialog:
1.12. Executing Vanilla OVS tests
If needed, recompile src for all OVS variants
$ cd src
$ make distclean
$ make
Update your 10_custom.conf file to use Vanilla OVS:
Run test:
$ ./vsperf --conf-file=<path_to_custom_conf>
Please note if you don’t want to configure Vanilla OVS through the
configuration file, you can pass it as a CLI argument.
$ ./vsperf --vswitch OvsVanilla
1.13. Executing tests with VMs
To run tests using vhost-user as guest access method:
Set VSWITCH and VNF of your settings file to:
VSWITCH = 'OvsDpdkVhost'
VNF = 'QemuDpdkVhost'
If needed, recompile src for all OVS variants
$ cd src
$ make distclean
$ make
Run test:
$ ./vsperf --conf-file=<path_to_custom_conf>/10_custom.conf
NOTE: By default vSwitch is acting as a server for dpdk vhost-user sockets.
In case, that QEMU should be a server for vhost-user sockets, then parameter
VSWITCH_VHOSTUSER_SERVER_MODE should be set to False.
1.14. Executing tests with VMs using Vanilla OVS
To run tests using Vanilla OVS:
Set the following variables:
VSWITCH = 'OvsVanilla'
VNF = 'QemuVirtioNet'
VANILLA_TGEN_PORT1_IP = n.n.n.n
VANILLA_TGEN_PORT1_MAC = nn:nn:nn:nn:nn:nn
VANILLA_TGEN_PORT2_IP = n.n.n.n
VANILLA_TGEN_PORT2_MAC = nn:nn:nn:nn:nn:nn
VANILLA_BRIDGE_IP = n.n.n.n
or use --test-params option
$ ./vsperf --conf-file=<path_to_custom_conf>/10_custom.conf \
--test-params "VANILLA_TGEN_PORT1_IP=n.n.n.n;" \
"VANILLA_TGEN_PORT1_MAC=nn:nn:nn:nn:nn:nn;" \
"VANILLA_TGEN_PORT2_IP=n.n.n.n;" \
"VANILLA_TGEN_PORT2_MAC=nn:nn:nn:nn:nn:nn"
If needed, recompile src for all OVS variants
$ cd src
$ make distclean
$ make
Run test:
$ ./vsperf --conf-file<path_to_custom_conf>/10_custom.conf
1.15. Executing VPP tests
Currently it is not possible to use standard scenario deployments for execution of
tests with VPP. It means, that deployments p2p, pvp, pvvp and in general any
PXP Deployment won’t work with VPP. However it is possible to use VPP in
Step driven tests. A basic set of VPP testcases covering phy2phy, pvp
and pvvp tests are already prepared.
List of performance tests with VPP support follows:
- phy2phy_tput_vpp: VPP: LTD.Throughput.RFC2544.PacketLossRatio
- phy2phy_cont_vpp: VPP: Phy2Phy Continuous Stream
- phy2phy_back2back_vpp: VPP: LTD.Throughput.RFC2544.BackToBackFrames
- pvp_tput_vpp: VPP: LTD.Throughput.RFC2544.PacketLossRatio
- pvp_cont_vpp: VPP: PVP Continuous Stream
- pvp_back2back_vpp: VPP: LTD.Throughput.RFC2544.BackToBackFrames
- pvvp_tput_vpp: VPP: LTD.Throughput.RFC2544.PacketLossRatio
- pvvp_cont_vpp: VPP: PVP Continuous Stream
- pvvp_back2back_vpp: VPP: LTD.Throughput.RFC2544.BackToBackFrames
In order to execute testcases with VPP it is required to:
After that it is possible to execute VPP testcases listed above.
For example:
$ ./vsperf --conf-file=<path_to_custom_conf> phy2phy_tput_vpp
1.16. Using vfio_pci with DPDK
To use vfio with DPDK instead of igb_uio add into your custom configuration
file the following parameter:
PATHS['dpdk']['src']['modules'] = ['uio', 'vfio-pci']
NOTE: In case, that DPDK is installed from binary package, then please
set PATHS['dpdk']['bin']['modules'] instead.
NOTE: Please ensure that Intel VT-d is enabled in BIOS.
NOTE: Please ensure your boot/grub parameters include
the following:
NOTE: In case of VPP, it is required to explicitly define, that vfio-pci
DPDK driver should be used. It means to update dpdk part of VSWITCH_VPP_ARGS
dictionary with uio-driver section, e.g. VSWITCH_VPP_ARGS[‘dpdk’] = ‘uio-driver vfio-pci’
To check that IOMMU is enabled on your platform:
$ dmesg | grep IOMMU
[ 0.000000] Intel-IOMMU: enabled
[ 0.139882] dmar: IOMMU 0: reg_base_addr fbffe000 ver 1:0 cap d2078c106f0466 ecap f020de
[ 0.139888] dmar: IOMMU 1: reg_base_addr ebffc000 ver 1:0 cap d2078c106f0466 ecap f020de
[ 0.139893] IOAPIC id 2 under DRHD base 0xfbffe000 IOMMU 0
[ 0.139894] IOAPIC id 0 under DRHD base 0xebffc000 IOMMU 1
[ 0.139895] IOAPIC id 1 under DRHD base 0xebffc000 IOMMU 1
[ 3.335744] IOMMU: dmar0 using Queued invalidation
[ 3.335746] IOMMU: dmar1 using Queued invalidation
....
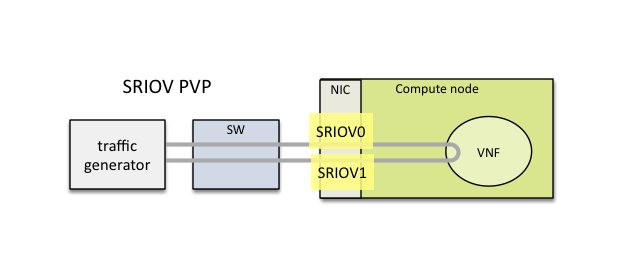
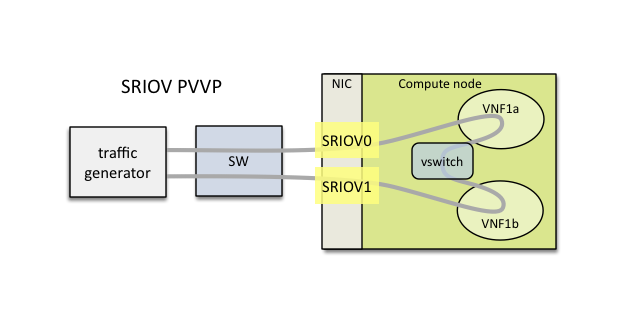
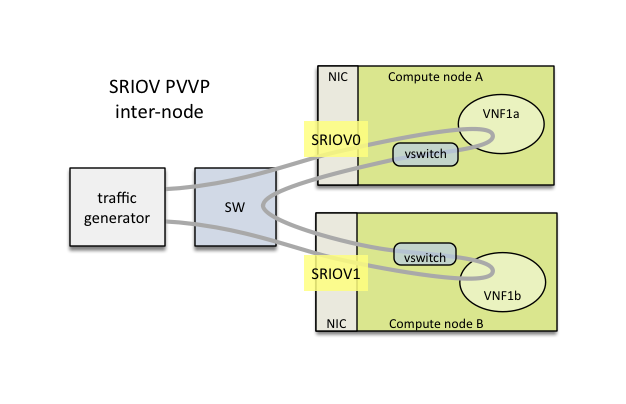
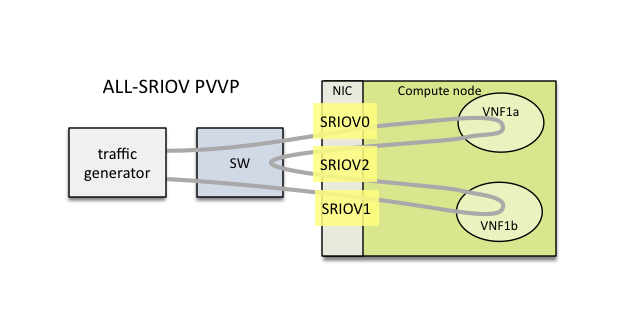
1.17. Using SRIOV support
To use virtual functions of NIC with SRIOV support, use extended form
of NIC PCI slot definition:
WHITELIST_NICS = ['0000:05:00.0|vf0', '0000:05:00.1|vf3']
Where ‘vf’ is an indication of virtual function usage and following
number defines a VF to be used. In case that VF usage is detected,
then vswitchperf will enable SRIOV support for given card and it will
detect PCI slot numbers of selected VFs.
So in example above, one VF will be configured for NIC ‘0000:05:00.0’
and four VFs will be configured for NIC ‘0000:05:00.1’. Vswitchperf
will detect PCI addresses of selected VFs and it will use them during
test execution.
At the end of vswitchperf execution, SRIOV support will be disabled.
SRIOV support is generic and it can be used in different testing scenarios.
For example:
- vSwitch tests with DPDK or without DPDK support to verify impact
of VF usage on vSwitch performance
- tests without vSwitch, where traffic is forwarded directly
between VF interfaces by packet forwarder (e.g. testpmd application)
- tests without vSwitch, where VM accesses VF interfaces directly
by PCI-passthrough to measure raw VM throughput performance.
1.18. Using QEMU with PCI passthrough support
Raw virtual machine throughput performance can be measured by execution of PVP
test with direct access to NICs by PCI pass-through. To execute VM with direct
access to PCI devices, enable vfio-pci. In order to use virtual functions,
SRIOV-support must be enabled.
Execution of test with PCI pass-through with vswitch disabled:
$ ./vsperf --conf-file=<path_to_custom_conf>/10_custom.conf \
--vswitch none --vnf QemuPciPassthrough pvp_tput
Any of supported guest-loopback-application can be used inside VM with
PCI pass-through support.
Note: Qemu with PCI pass-through support can be used only with PVP test
deployment.
1.19. Selection of loopback application for tests with VMs
To select the loopback applications which will forward packets inside VMs,
the following parameter should be configured:
GUEST_LOOPBACK = ['testpmd']
or use --test-params CLI argument:
$ ./vsperf --conf-file=<path_to_custom_conf>/10_custom.conf \
--test-params "GUEST_LOOPBACK=['testpmd']"
Supported loopback applications are:
'testpmd' - testpmd from dpdk will be built and used
'l2fwd' - l2fwd module provided by Huawei will be built and used
'linux_bridge' - linux bridge will be configured
'buildin' - nothing will be configured by vsperf; VM image must
ensure traffic forwarding between its interfaces
Guest loopback application must be configured, otherwise traffic
will not be forwarded by VM and testcases with VM related deployments
will fail. Guest loopback application is set to ‘testpmd’ by default.
NOTE: In case that only 1 or more than 2 NICs are configured for VM,
then ‘testpmd’ should be used. As it is able to forward traffic between
multiple VM NIC pairs.
NOTE: In case of linux_bridge, all guest NICs are connected to the same
bridge inside the guest.
1.20. Mergable Buffers Options with QEMU
Mergable buffers can be disabled with VSPerf within QEMU. This option can
increase performance significantly when not using jumbo frame sized packets.
By default VSPerf disables mergable buffers. If you wish to enable it you
can modify the setting in the a custom conf file.
GUEST_NIC_MERGE_BUFFERS_DISABLE = [False]
Then execute using the custom conf file.
$ ./vsperf --conf-file=<path_to_custom_conf>/10_custom.conf
Alternatively you can just pass the param during execution.
$ ./vsperf --test-params "GUEST_NIC_MERGE_BUFFERS_DISABLE=[False]"
1.21. Selection of dpdk binding driver for tests with VMs
To select dpdk binding driver, which will specify which driver the vm NICs will
use for dpdk bind, the following configuration parameter should be configured:
GUEST_DPDK_BIND_DRIVER = ['igb_uio_from_src']
The supported dpdk guest bind drivers are:
'uio_pci_generic' - Use uio_pci_generic driver
'igb_uio_from_src' - Build and use the igb_uio driver from the dpdk src
files
'vfio_no_iommu' - Use vfio with no iommu option. This requires custom
guest images that support this option. The default
vloop image does not support this driver.
Note: uio_pci_generic does not support sr-iov testcases with guests attached.
This is because uio_pci_generic only supports legacy interrupts. In case
uio_pci_generic is selected with the vnf as QemuPciPassthrough it will be
modified to use igb_uio_from_src instead.
Note: vfio_no_iommu requires kernels equal to or greater than 4.5 and dpdk
16.04 or greater. Using this option will also taint the kernel.
Please refer to the dpdk documents at http://dpdk.org/doc/guides for more
information on these drivers.
1.22. Guest Core and Thread Binding
VSPERF provides options to achieve better performance by guest core binding and
guest vCPU thread binding as well. Core binding is to bind all the qemu threads.
Thread binding is to bind the house keeping threads to some CPU and vCPU thread to
some other CPU, this helps to reduce the noise from qemu house keeping threads.
GUEST_CORE_BINDING = [('#EVAL(6+2*#VMINDEX)', '#EVAL(7+2*#VMINDEX)')]
NOTE By default the GUEST_THREAD_BINDING will be none, which means same as
the GUEST_CORE_BINDING, i.e. the vcpu threads are sharing the physical CPUs with
the house keeping threads. Better performance using vCPU thread binding can be
achieved by enabling affinity in the custom configuration file.
For example, if an environment requires 32,33 to be core binded and 29,30&31 for
guest thread binding to achieve better performance.
VNF_AFFINITIZATION_ON = True
GUEST_CORE_BINDING = [('32','33')]
GUEST_THREAD_BINDING = [('29', '30', '31')]
1.23. Qemu CPU features
QEMU default to a compatible subset of performance enhancing cpu features.
To pass all available host processor features to the guest.
GUEST_CPU_OPTIONS = ['host,migratable=off']
NOTE To enhance the performance, cpu features tsc deadline timer for guest,
the guest PMU, the invariant TSC can be provided in the custom configuration file.
1.24. Multi-Queue Configuration
VSPerf currently supports multi-queue with the following limitations:
Requires QEMU 2.5 or greater and any OVS version higher than 2.5. The
default upstream package versions installed by VSPerf satisfies this
requirement.
Guest image must have ethtool utility installed if using l2fwd or linux
bridge inside guest for loopback.
If using OVS versions 2.5.0 or less enable old style multi-queue as shown
in the ‘‘02_vswitch.conf’’ file.
To enable multi-queue for dpdk modify the ‘‘02_vswitch.conf’’ file.
VSWITCH_DPDK_MULTI_QUEUES = 2
NOTE: you should consider using the switch affinity to set a pmd cpu mask
that can optimize your performance. Consider the numa of the NIC in use if this
applies by checking /sys/class/net/<eth_name>/device/numa_node and setting an
appropriate mask to create PMD threads on the same numa node.
When multi-queue is enabled, each dpdk or dpdkvhostuser port that is created
on the switch will set the option for multiple queues. If old style multi queue
has been enabled a global option for multi queue will be used instead of the
port by port option.
To enable multi-queue on the guest modify the ‘‘04_vnf.conf’’ file.
Enabling multi-queue at the guest will add multiple queues to each NIC port when
qemu launches the guest.
In case of Vanilla OVS, multi-queue is enabled on the tuntap ports and nic
queues will be enabled inside the guest with ethtool. Simply enabling the
multi-queue on the guest is sufficient for Vanilla OVS multi-queue.
Testpmd should be configured to take advantage of multi-queue on the guest if
using DPDKVhostUser. This can be done by modifying the ‘‘04_vnf.conf’’ file.
GUEST_TESTPMD_PARAMS = ['-l 0,1,2,3,4 -n 4 --socket-mem 512 -- '
'--burst=64 -i --txqflags=0xf00 '
'--nb-cores=4 --rxq=2 --txq=2 '
'--disable-hw-vlan']
NOTE: The guest SMP cores must be configured to allow for testpmd to use the
optimal number of cores to take advantage of the multiple guest queues.
In case of using Vanilla OVS and qemu virtio-net you can increase performance
by binding vhost-net threads to cpus. This can be done by enabling the affinity
in the ‘‘04_vnf.conf’’ file. This can be done to non multi-queue enabled
configurations as well as there will be 2 vhost-net threads.
VSWITCH_VHOST_NET_AFFINITIZATION = True
VSWITCH_VHOST_CPU_MAP = [4,5,8,11]
NOTE: This method of binding would require a custom script in a real
environment.
NOTE: For optimal performance guest SMPs and/or vhost-net threads should be
on the same numa as the NIC in use if possible/applicable. Testpmd should be
assigned at least (nb_cores +1) total cores with the cpu mask.
1.25. Jumbo Frame Testing
VSPERF provides options to support jumbo frame testing with a jumbo frame supported
NIC and traffic generator for the following vswitches:
- OVSVanilla
- OvsDpdkVhostUser
- TestPMD loopback with or without a guest
NOTE: There is currently no support for SR-IOV or VPP at this time with jumbo
frames.
All packet forwarding applications for pxp testing is supported.
To enable jumbo frame testing simply enable the option in the conf files and set the
maximum size that will be used.
VSWITCH_JUMBO_FRAMES_ENABLED = True
VSWITCH_JUMBO_FRAMES_SIZE = 9000
To enable jumbo frame testing with OVSVanilla the NIC in test on the host must have
its mtu size changed manually using ifconfig or applicable tools:
ifconfig eth1 mtu 9000 up
NOTE: To make the setting consistent across reboots you should reference the OS
documents as it differs from distribution to distribution.
To start a test for jumbo frames modify the conf file packet sizes or pass the option
through the VSPERF command line.
TEST_PARAMS = {'TRAFFICGEN_PKT_SIZES':(2000,9000)}
./vsperf --test-params "TRAFFICGEN_PKT_SIZES=2000,9000"
It is recommended to increase the memory size for OvsDpdkVhostUser testing from the default
1024. Your size required may vary depending on the number of guests in your testing. 4096
appears to work well for most typical testing scenarios.
DPDK_SOCKET_MEM = ['4096', '0']
NOTE: For Jumbo frames to work with DpdkVhostUser, mergable buffers will be enabled by
default. If testing with mergable buffers in QEMU is desired, disable Jumbo Frames and only
test non jumbo frame sizes. Test Jumbo Frames sizes separately to avoid this collision.
1.26. Executing Packet Forwarding tests
To select the applications which will forward packets,
the following parameters should be configured:
VSWITCH = 'none'
PKTFWD = 'TestPMD'
or use --vswitch and --fwdapp CLI arguments:
$ ./vsperf phy2phy_cont --conf-file user_settings.py \
--vswitch none \
--fwdapp TestPMD
Supported Packet Forwarding applications are:
'testpmd' - testpmd from dpdk
Update your ‘‘10_custom.conf’’ file to use the appropriate variables
for selected Packet Forwarder:
# testpmd configuration
TESTPMD_ARGS = []
# packet forwarding mode supported by testpmd; Please see DPDK documentation
# for comprehensive list of modes supported by your version.
# e.g. io|mac|mac_retry|macswap|flowgen|rxonly|txonly|csum|icmpecho|...
# Note: Option "mac_retry" has been changed to "mac retry" since DPDK v16.07
TESTPMD_FWD_MODE = 'csum'
# checksum calculation layer: ip|udp|tcp|sctp|outer-ip
TESTPMD_CSUM_LAYER = 'ip'
# checksum calculation place: hw (hardware) | sw (software)
TESTPMD_CSUM_CALC = 'sw'
# recognize tunnel headers: on|off
TESTPMD_CSUM_PARSE_TUNNEL = 'off'
Run test:
$ ./vsperf phy2phy_tput --conf-file <path_to_settings_py>
1.27. Executing Packet Forwarding tests with one guest
TestPMD with DPDK 16.11 or greater can be used to forward packets as a switch to a single guest using TestPMD vdev
option. To set this configuration the following parameters should be used.
VSWITCH = 'none'
PKTFWD = 'TestPMD'
or use --vswitch and --fwdapp CLI arguments:
$ ./vsperf pvp_tput --conf-file user_settings.py \
--vswitch none \
--fwdapp TestPMD
Guest forwarding application only supports TestPMD in this configuration.
GUEST_LOOPBACK = ['testpmd']
For optimal performance one cpu per port +1 should be used for TestPMD. Also set additional params for packet forwarding
application to use the correct number of nb-cores.
DPDK_SOCKET_MEM = ['1024', '0']
VSWITCHD_DPDK_ARGS = ['-l', '46,44,42,40,38', '-n', '4']
TESTPMD_ARGS = ['--nb-cores=4', '--txq=1', '--rxq=1']
For guest TestPMD 3 VCpus should be assigned with the following TestPMD params.
GUEST_TESTPMD_PARAMS = ['-l 0,1,2 -n 4 --socket-mem 1024 -- '
'--burst=64 -i --txqflags=0xf00 '
'--disable-hw-vlan --nb-cores=2 --txq=1 --rxq=1']
Execution of TestPMD can be run with the following command line
./vsperf pvp_tput --vswitch=none --fwdapp=TestPMD --conf-file <path_to_settings_py>
NOTE: To achieve the best 0% loss numbers with rfc2544 throughput testing, other tunings should be applied to host
and guest such as tuned profiles and CPU tunings to prevent possible interrupts to worker threads.
1.28. VSPERF modes of operation
VSPERF can be run in different modes. By default it will configure vSwitch,
traffic generator and VNF. However it can be used just for configuration
and execution of traffic generator. Another option is execution of all
components except traffic generator itself.
Mode of operation is driven by configuration parameter -m or –mode
-m MODE, --mode MODE vsperf mode of operation;
Values:
"normal" - execute vSwitch, VNF and traffic generator
"trafficgen" - execute only traffic generator
"trafficgen-off" - execute vSwitch and VNF
"trafficgen-pause" - execute vSwitch and VNF but wait before traffic transmission
In case, that VSPERF is executed in “trafficgen” mode, then configuration
of traffic generator can be modified through TRAFFIC dictionary passed to the
--test-params option. It is not needed to specify all values of TRAFFIC
dictionary. It is sufficient to specify only values, which should be changed.
Detailed description of TRAFFIC dictionary can be found at
Configuration of TRAFFIC dictionary.
Example of execution of VSPERF in “trafficgen” mode:
$ ./vsperf -m trafficgen --trafficgen IxNet --conf-file vsperf.conf \
--test-params "TRAFFIC={'traffic_type':'rfc2544_continuous','bidir':'False','framerate':60}"
1.29. Code change verification by pylint
Every developer participating in VSPERF project should run
pylint before his python code is submitted for review. Project
specific configuration for pylint is available at ‘pylint.rc’.
Example of manual pylint invocation:
$ pylint --rcfile ./pylintrc ./vsperf
1.30. GOTCHAs:
1.30.1. Custom image fails to boot
Using custom VM images may not boot within VSPerf pxp testing because of
the drive boot and shared type which could be caused by a missing scsi
driver inside the image. In case of issues you can try changing the drive
boot type to ide.
GUEST_BOOT_DRIVE_TYPE = ['ide']
GUEST_SHARED_DRIVE_TYPE = ['ide']
1.30.2. OVS with DPDK and QEMU
If you encounter the following error: “before (last 100 chars):
‘-path=/dev/hugepages,share=on: unable to map backing store for
hugepages: Cannot allocate memoryrnrn” during qemu initialization,
check the amount of hugepages on your system:
$ cat /proc/meminfo | grep HugePages
By default the vswitchd is launched with 1Gb of memory, to change
this, modify –socket-mem parameter in conf/02_vswitch.conf to allocate
an appropriate amount of memory:
DPDK_SOCKET_MEM = ['1024', '0']
VSWITCHD_DPDK_ARGS = ['-c', '0x4', '-n', '4']
VSWITCHD_DPDK_CONFIG = {
'dpdk-init' : 'true',
'dpdk-lcore-mask' : '0x4',
'dpdk-socket-mem' : '1024,0',
}
Note: Option VSWITCHD_DPDK_ARGS is used for vswitchd, which supports --dpdk
parameter. In recent vswitchd versions, option VSWITCHD_DPDK_CONFIG will be
used to configure vswitchd via ovs-vsctl calls.
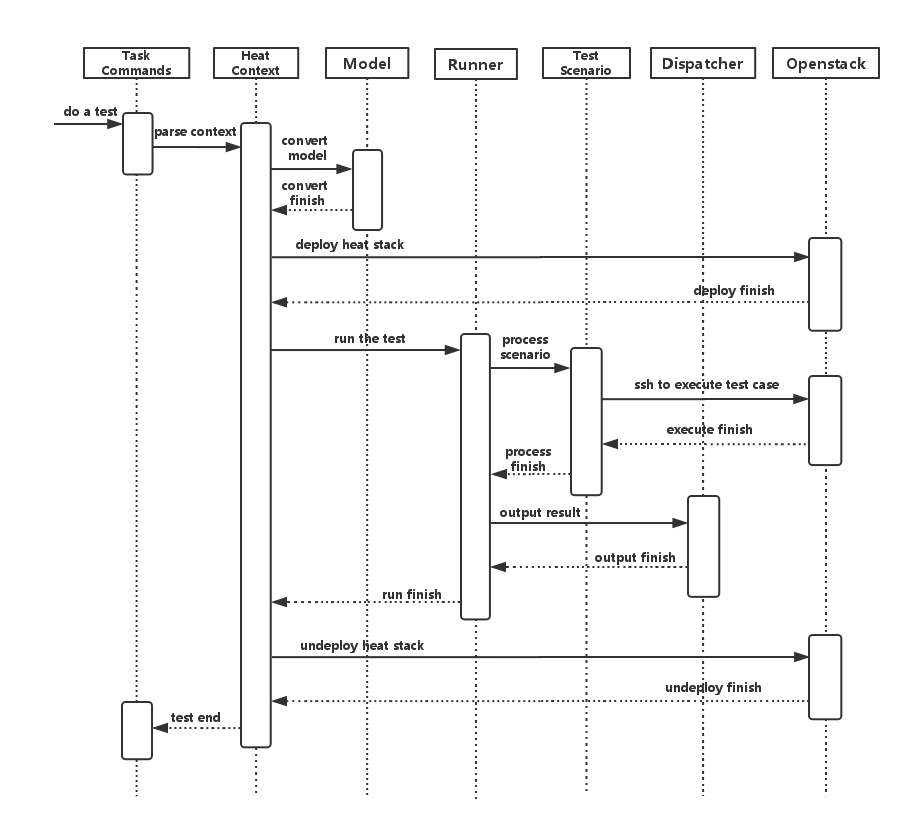
2. Step driven tests
In general, test scenarios are defined by a deployment used in the particular
test case definition. The chosen deployment scenario will take care of the vSwitch
configuration, deployment of VNFs and it can also affect configuration of a traffic
generator. In order to allow a more flexible way of testcase scripting, VSPERF supports
a detailed step driven testcase definition. It can be used to configure and
program vSwitch, deploy and terminate VNFs, execute a traffic generator,
modify a VSPERF configuration, execute external commands, etc.
Execution of step driven tests is done on a step by step work flow starting
with step 0 as defined inside the test case. Each step of the test increments
the step number by one which is indicated in the log.
(testcases.integration) - Step 0 'vswitch add_vport ['br0']' start
Step driven tests can be used for both performance and integration testing.
In case of integration test, each step in the test case is validated. If a step
does not pass validation the test will fail and terminate. The test will continue
until a failure is detected or all steps pass. A csv report file is generated after
a test completes with an OK or FAIL result.
NOTE: It is possible to suppress validation process of given step by prefixing
it by ! (exclamation mark).
In following example test execution won’t fail if all traffic is dropped:
['!trafficgen', 'send_traffic', {}]
In case of performance test, the validation of steps is not performed and
standard output files with results from traffic generator and underlying OS
details are generated by vsperf.
Step driven testcases can be used in two different ways:
- # description of full testcase - in this case
clean deployment is used
- to indicate that vsperf should neither configure vSwitch nor deploy any VNF.
Test shall perform all required vSwitch configuration and programming and
deploy required number of VNFs.
- # modification of existing deployment - in this case, any of supported
- deployments can be used to perform initial vSwitch configuration and
deployment of VNFs. Additional actions defined by TestSteps can be used
to alter vSwitch configuration or deploy additional VNFs. After the last
step is processed, the test execution will continue with traffic execution.
2.1. Test objects and their functions
Every test step can call a function of one of the supported test objects. The list
of supported objects and their most common functions follows:
vswitch - provides functions for vSwitch configuration
List of supported functions:
add_switch br_name - creates a new switch (bridge) with given br_namedel_switch br_name - deletes switch (bridge) with given br_nameadd_phy_port br_name - adds a physical port into bridge specified by br_nameadd_vport br_name - adds a virtual port into bridge specified by br_namedel_port br_name port_name - removes physical or virtual port specified by
port_name from bridge br_nameadd_flow br_name flow - adds flow specified by flow dictionary into
the bridge br_name; Content of flow dictionary will be passed to the vSwitch.
In case of Open vSwitch it will be passed to the ovs-ofctl add-flow command.
Please see Open vSwitch documentation for the list of supported flow parameters.del_flow br_name [flow] - deletes flow specified by flow dictionary from
bridge br_name; In case that optional parameter flow is not specified
or set to an empty dictionary {}, then all flows from bridge br_name
will be deleted.dump_flows br_name - dumps all flows from bridge specified by br_nameenable_stp br_name - enables Spanning Tree Protocol for bridge br_namedisable_stp br_name - disables Spanning Tree Protocol for bridge br_nameenable_rstp br_name - enables Rapid Spanning Tree Protocol for bridge br_namedisable_rstp br_name - disables Rapid Spanning Tree Protocol for bridge br_namerestart - restarts switch, which is useful for failover testcases
Examples:
['vswitch', 'add_switch', 'int_br0']
['vswitch', 'del_switch', 'int_br0']
['vswitch', 'add_phy_port', 'int_br0']
['vswitch', 'del_port', 'int_br0', '#STEP[2][0]']
['vswitch', 'add_flow', 'int_br0', {'in_port': '1', 'actions': ['output:2'],
'idle_timeout': '0'}],
['vswitch', 'enable_rstp', 'int_br0']
vnf[ID] - provides functions for deployment and termination of VNFs; Optional
alfanumerical ID is used for VNF identification in case that testcase
deploys multiple VNFs.
List of supported functions:
start - starts a VNF based on VSPERF configurationstop - gracefully terminates given VNFexecute command [delay] - executes command cmd inside VNF; Optional
delay defines number of seconds to wait before next step is executed. Method
returns command output as a string.execute_and_wait command [timeout] [prompt] - executes command cmd inside
VNF; Optional timeout defines number of seconds to wait until prompt is detected.
Optional prompt defines a string, which is used as detection of successful command
execution. In case that prompt is not defined, then content of GUEST_PROMPT_LOGIN
parameter will be used. Method returns command output as a string.
Examples:
['vnf1', 'start'],
['vnf2', 'start'],
['vnf1', 'execute_and_wait', 'ifconfig eth0 5.5.5.1/24 up'],
['vnf2', 'execute_and_wait', 'ifconfig eth0 5.5.5.2/24 up', 120, 'root.*#'],
['vnf2', 'execute_and_wait', 'ping -c1 5.5.5.1'],
['vnf2', 'stop'],
['vnf1', 'stop'],
trafficgen - triggers traffic generation
List of supported functions:
send_traffic traffic - starts a traffic based on the vsperf configuration
and given traffic dictionary. More details about traffic dictionary
and its possible values are available at Traffic Generator Integration Guideget_results - returns dictionary with results collected from previous execution
of send_traffic
Examples:
['trafficgen', 'send_traffic', {'traffic_type' : 'rfc2544_throughput'}]
['trafficgen', 'send_traffic', {'traffic_type' : 'rfc2544_back2back', 'bidir' : 'True'}],
['trafficgen', 'get_results'],
['tools', 'assert', '#STEP[-1][0]["frame_loss_percent"] < 0.05'],
settings - reads or modifies VSPERF configuration
List of supported functions:
getValue param - returns value of given paramsetValue param value - sets value of param to given value
Examples:
['settings', 'getValue', 'TOOLS']
['settings', 'setValue', 'GUEST_USERNAME', ['root']]
It is possible and more convenient to access any VSPERF configuration option directly
via $NAME notation. Option evaluation is done during runtime and vsperf will
automatically translate it to the appropriate call of settings.getValue.
If the referred parameter does not exist, then vsperf will keep $NAME
string untouched and it will continue with testcase execution. The reason is to
avoid test execution failure in case that $ sign has been used from different
reason than vsperf parameter evaluation.
NOTE: It is recommended to use ${NAME} notation for any shell parameters
used within Exec_Shell call to avoid a clash with configuration parameter
evaluation.
NOTE: It is possible to refer to vsperf parameter value by #PARAM() macro
(see Referencing parameter values. However #PARAM() macro is
evaluated at the beginning of vsperf execution and it will not reflect any changes
made to the vsperf configuration during runtime. On the other hand $NAME
notation is evaluated during test execution and thus it contains any modifications
to the configuration parameter made by vsperf (e.g. TOOLS and NICS
dictionaries) or by testcase definition (e.g. TRAFFIC dictionary).
Examples:
['tools', 'exec_shell', "$TOOLS['ovs-vsctl'] show"]
['settings', 'setValue', 'TRAFFICGEN_IXIA_PORT2', '$TRAFFICGEN_IXIA_PORT1'],
['vswitch', 'add_flow', 'int_br0',
{'in_port': '#STEP[1][1]',
'dl_type': '0x800',
'nw_proto': '17',
'nw_dst': '$TRAFFIC["l3"]["dstip"]/8',
'actions': ['output:#STEP[2][1]']
}
]
namespace - creates or modifies network namespaces
List of supported functions:
create_namespace name - creates new namespace with given namedelete_namespace name - deletes namespace specified by its nameassign_port_to_namespace port name [port_up] - assigns NIC specified by port
into given namespace name; If optional parameter port_up is set to True,
then port will be brought up.add_ip_to_namespace_eth port name addr cidr - assigns an IP address addr/cidr
to the NIC specified by port within namespace namereset_port_to_root port name - returns given port from namespace name back
to the root namespace
Examples:
['namespace', 'create_namespace', 'testns']
['namespace', 'assign_port_to_namespace', 'eth0', 'testns']
veth - manipulates with eth and veth devices
List of supported functions:
add_veth_port port peer_port - adds a pair of veth ports named port and
peer_portdel_veth_port port peer_port - deletes a veth port pair specified by port
and peer_portbring_up_eth_port eth_port [namespace] - brings up eth_port in (optional)
namespace
Examples:
['veth', 'add_veth_port', 'veth', 'veth1']
['veth', 'bring_up_eth_port', 'eth1']
tools - provides a set of helper functions
List of supported functions:
Assert condition - evaluates given condition and raises AssertionError
in case that condition is not TrueEval expression - evaluates given expression as a python code and returns
its resultExec_Shell command - executes a shell commandExec_Python code - executes a python code
Examples:
['tools', 'exec_shell', 'numactl -H', 'available: ([0-9]+)']
['tools', 'assert', '#STEP[-1][0]>1']
wait - is used for test case interruption. This object doesn’t have
any functions. Once reached, vsperf will pause test execution and waits
for press of Enter key. It can be used during testcase design
for debugging purposes.
Examples:
sleep - is used to pause testcase execution for defined number of seconds.
Examples:
log level message - is used to log message of given level into vsperf output.
Level is one of info, debug, warning or error.
Examples:
['log', 'error', 'tools $TOOLS']
pdb - executes python debugger
Examples:
2.2. Test Macros
Test profiles can include macros as part of the test step. Each step in the
profile may return a value such as a port name. Recall macros use #STEP to
indicate the recalled value inside the return structure. If the method the
test step calls returns a value it can be later recalled, for example:
{
"Name": "vswitch_add_del_vport",
"Deployment": "clean",
"Description": "vSwitch - add and delete virtual port",
"TestSteps": [
['vswitch', 'add_switch', 'int_br0'], # STEP 0
['vswitch', 'add_vport', 'int_br0'], # STEP 1
['vswitch', 'del_port', 'int_br0', '#STEP[1][0]'], # STEP 2
['vswitch', 'del_switch', 'int_br0'], # STEP 3
]
}
This test profile uses the vswitch add_vport method which returns a string
value of the port added. This is later called by the del_port method using the
name from step 1.
It is also possible to use negative indexes in step macros. In that case
#STEP[-1] will refer to the result from previous step, #STEP[-2]
will refer to result of step called before previous step, etc. It means,
that you could change STEP 2 from previous example to achieve the same
functionality:
['vswitch', 'del_port', 'int_br0', '#STEP[-1][0]'], # STEP 2
Another option to refer to previous values, is to define an alias for given step
by its first argument with ‘#’ prefix. Alias must be unique and it can’t be a number.
Example of step alias usage:
['#port1', 'vswitch', 'add_vport', 'int_br0'],
['vswitch', 'del_port', 'int_br0', '#STEP[port1][0]'],
Also commonly used steps can be created as a separate profile.
STEP_VSWITCH_PVP_INIT = [
['vswitch', 'add_switch', 'int_br0'], # STEP 0
['vswitch', 'add_phy_port', 'int_br0'], # STEP 1
['vswitch', 'add_phy_port', 'int_br0'], # STEP 2
['vswitch', 'add_vport', 'int_br0'], # STEP 3
['vswitch', 'add_vport', 'int_br0'], # STEP 4
]
This profile can then be used inside other testcases
{
"Name": "vswitch_pvp",
"Deployment": "clean",
"Description": "vSwitch - configure switch and one vnf",
"TestSteps": STEP_VSWITCH_PVP_INIT +
[
['vnf', 'start'],
['vnf', 'stop'],
] +
STEP_VSWITCH_PVP_FINIT
}
It is possible to refer to vsperf configuration parameters within step macros. Please
see step-driven-tests-variable-usage for more details.
In case that step returns a string or list of strings, then it is possible to
filter such output by regular expression. This optional filter can be specified
as a last step parameter with prefix ‘|’. Output will be split into separate lines
and only matching records will be returned. It is also possible to return a specified
group of characters from the matching lines, e.g. by regex |ID (\d+).
Examples:
['tools', 'exec_shell', "sudo $TOOLS['ovs-appctl'] dpif-netdev/pmd-rxq-show",
'|dpdkvhostuser0\s+queue-id: \d'],
['tools', 'assert', 'len(#STEP[-1])==1'],
['vnf', 'execute_and_wait', 'ethtool -L eth0 combined 2'],
['vnf', 'execute_and_wait', 'ethtool -l eth0', '|Combined:\s+2'],
['tools', 'assert', 'len(#STEP[-1])==2']
2.3. HelloWorld and other basic Testcases
The following examples are for demonstration purposes.
You can run them by copying and pasting into the
conf/integration/01_testcases.conf file.
A command-line instruction is shown at the end of each
example.
2.3.1. HelloWorld
The first example is a HelloWorld testcase.
It simply creates a bridge with 2 physical ports, then sets up a flow to drop
incoming packets from the port that was instantiated at the STEP #1.
There’s no interaction with the traffic generator.
Then the flow, the 2 ports and the bridge are deleted.
‘add_phy_port’ method creates a ‘dpdk’ type interface that will manage the
physical port. The string value returned is the port name that will be referred
by ‘del_port’ later on.
{
"Name": "HelloWorld",
"Description": "My first testcase",
"Deployment": "clean",
"TestSteps": [
['vswitch', 'add_switch', 'int_br0'], # STEP 0
['vswitch', 'add_phy_port', 'int_br0'], # STEP 1
['vswitch', 'add_phy_port', 'int_br0'], # STEP 2
['vswitch', 'add_flow', 'int_br0', {'in_port': '#STEP[1][1]', \
'actions': ['drop'], 'idle_timeout': '0'}],
['vswitch', 'del_flow', 'int_br0'],
['vswitch', 'del_port', 'int_br0', '#STEP[1][0]'],
['vswitch', 'del_port', 'int_br0', '#STEP[2][0]'],
['vswitch', 'del_switch', 'int_br0'],
]
},
To run HelloWorld test:
./vsperf --conf-file user_settings.py --integration HelloWorld
2.3.2. Specify a Flow by the IP address
The next example shows how to explicitly set up a flow by specifying a
destination IP address.
All packets received from the port created at STEP #1 that have a destination
IP address = 90.90.90.90 will be forwarded to the port created at the STEP #2.
{
"Name": "p2p_rule_l3da",
"Description": "Phy2Phy with rule on L3 Dest Addr",
"Deployment": "clean",
"biDirectional": "False",
"TestSteps": [
['vswitch', 'add_switch', 'int_br0'], # STEP 0
['vswitch', 'add_phy_port', 'int_br0'], # STEP 1
['vswitch', 'add_phy_port', 'int_br0'], # STEP 2
['vswitch', 'add_flow', 'int_br0', {'in_port': '#STEP[1][1]', \
'dl_type': '0x0800', 'nw_dst': '90.90.90.90', \
'actions': ['output:#STEP[2][1]'], 'idle_timeout': '0'}],
['trafficgen', 'send_traffic', \
{'traffic_type' : 'rfc2544_continuous'}],
['vswitch', 'dump_flows', 'int_br0'], # STEP 5
['vswitch', 'del_flow', 'int_br0'], # STEP 7 == del-flows
['vswitch', 'del_port', 'int_br0', '#STEP[1][0]'],
['vswitch', 'del_port', 'int_br0', '#STEP[2][0]'],
['vswitch', 'del_switch', 'int_br0'],
]
},
To run the test:
./vsperf --conf-file user_settings.py --integration p2p_rule_l3da
2.3.3. Multistream feature
The next testcase uses the multistream feature.
The traffic generator will send packets with different UDP ports.
That is accomplished by using “Stream Type” and “MultiStream” keywords.
4 different flows are set to forward all incoming packets.
{
"Name": "multistream_l4",
"Description": "Multistream on UDP ports",
"Deployment": "clean",
"Parameters": {
'TRAFFIC' : {
"multistream": 4,
"stream_type": "L4",
},
},
"TestSteps": [
['vswitch', 'add_switch', 'int_br0'], # STEP 0
['vswitch', 'add_phy_port', 'int_br0'], # STEP 1
['vswitch', 'add_phy_port', 'int_br0'], # STEP 2
# Setup Flows
['vswitch', 'add_flow', 'int_br0', {'in_port': '#STEP[1][1]', \
'dl_type': '0x0800', 'nw_proto': '17', 'udp_dst': '0', \
'actions': ['output:#STEP[2][1]'], 'idle_timeout': '0'}],
['vswitch', 'add_flow', 'int_br0', {'in_port': '#STEP[1][1]', \
'dl_type': '0x0800', 'nw_proto': '17', 'udp_dst': '1', \
'actions': ['output:#STEP[2][1]'], 'idle_timeout': '0'}],
['vswitch', 'add_flow', 'int_br0', {'in_port': '#STEP[1][1]', \
'dl_type': '0x0800', 'nw_proto': '17', 'udp_dst': '2', \
'actions': ['output:#STEP[2][1]'], 'idle_timeout': '0'}],
['vswitch', 'add_flow', 'int_br0', {'in_port': '#STEP[1][1]', \
'dl_type': '0x0800', 'nw_proto': '17', 'udp_dst': '3', \
'actions': ['output:#STEP[2][1]'], 'idle_timeout': '0'}],
# Send mono-dir traffic
['trafficgen', 'send_traffic', \
{'traffic_type' : 'rfc2544_continuous', \
'bidir' : 'False'}],
# Clean up
['vswitch', 'del_flow', 'int_br0'],
['vswitch', 'del_port', 'int_br0', '#STEP[1][0]'],
['vswitch', 'del_port', 'int_br0', '#STEP[2][0]'],
['vswitch', 'del_switch', 'int_br0'],
]
},
To run the test:
./vsperf --conf-file user_settings.py --integration multistream_l4
2.3.4. PVP with a VM Replacement
This example launches a 1st VM in a PVP topology, then the VM is replaced
by another VM.
When VNF setup parameter in ./conf/04_vnf.conf is “QemuDpdkVhostUser”
‘add_vport’ method creates a ‘dpdkvhostuser’ type port to connect a VM.
{
"Name": "ex_replace_vm",
"Description": "PVP with VM replacement",
"Deployment": "clean",
"TestSteps": [
['vswitch', 'add_switch', 'int_br0'], # STEP 0
['vswitch', 'add_phy_port', 'int_br0'], # STEP 1
['vswitch', 'add_phy_port', 'int_br0'], # STEP 2
['vswitch', 'add_vport', 'int_br0'], # STEP 3 vm1
['vswitch', 'add_vport', 'int_br0'], # STEP 4
# Setup Flows
['vswitch', 'add_flow', 'int_br0', {'in_port': '#STEP[1][1]', \
'actions': ['output:#STEP[3][1]'], 'idle_timeout': '0'}],
['vswitch', 'add_flow', 'int_br0', {'in_port': '#STEP[4][1]', \
'actions': ['output:#STEP[2][1]'], 'idle_timeout': '0'}],
['vswitch', 'add_flow', 'int_br0', {'in_port': '#STEP[2][1]', \
'actions': ['output:#STEP[4][1]'], 'idle_timeout': '0'}],
['vswitch', 'add_flow', 'int_br0', {'in_port': '#STEP[3][1]', \
'actions': ['output:#STEP[1][1]'], 'idle_timeout': '0'}],
# Start VM 1
['vnf1', 'start'],
# Now we want to replace VM 1 with another VM
['vnf1', 'stop'],
['vswitch', 'add_vport', 'int_br0'], # STEP 11 vm2
['vswitch', 'add_vport', 'int_br0'], # STEP 12
['vswitch', 'del_flow', 'int_br0'],
['vswitch', 'add_flow', 'int_br0', {'in_port': '#STEP[1][1]', \
'actions': ['output:#STEP[11][1]'], 'idle_timeout': '0'}],
['vswitch', 'add_flow', 'int_br0', {'in_port': '#STEP[12][1]', \
'actions': ['output:#STEP[2][1]'], 'idle_timeout': '0'}],
# Start VM 2
['vnf2', 'start'],
['vnf2', 'stop'],
['vswitch', 'dump_flows', 'int_br0'],
# Clean up
['vswitch', 'del_flow', 'int_br0'],
['vswitch', 'del_port', 'int_br0', '#STEP[1][0]'],
['vswitch', 'del_port', 'int_br0', '#STEP[2][0]'],
['vswitch', 'del_port', 'int_br0', '#STEP[3][0]'], # vm1
['vswitch', 'del_port', 'int_br0', '#STEP[4][0]'],
['vswitch', 'del_port', 'int_br0', '#STEP[11][0]'], # vm2
['vswitch', 'del_port', 'int_br0', '#STEP[12][0]'],
['vswitch', 'del_switch', 'int_br0'],
]
},
To run the test:
./vsperf --conf-file user_settings.py --integration ex_replace_vm
2.3.5. VM with a Linux bridge
This example setups a PVP topology and routes traffic to the VM based on
the destination IP address. A command-line parameter is used to select a Linux
bridge as a guest loopback application. It is also possible to select a guest
loopback application by a configuration option GUEST_LOOPBACK.
{
"Name": "ex_pvp_rule_l3da",
"Description": "PVP with flow on L3 Dest Addr",
"Deployment": "clean",
"TestSteps": [
['vswitch', 'add_switch', 'int_br0'], # STEP 0
['vswitch', 'add_phy_port', 'int_br0'], # STEP 1
['vswitch', 'add_phy_port', 'int_br0'], # STEP 2
['vswitch', 'add_vport', 'int_br0'], # STEP 3 vm1
['vswitch', 'add_vport', 'int_br0'], # STEP 4
# Setup Flows
['vswitch', 'add_flow', 'int_br0', {'in_port': '#STEP[1][1]', \
'dl_type': '0x0800', 'nw_dst': '90.90.90.90', \
'actions': ['output:#STEP[3][1]'], 'idle_timeout': '0'}],
# Each pkt from the VM is forwarded to the 2nd dpdk port
['vswitch', 'add_flow', 'int_br0', {'in_port': '#STEP[4][1]', \
'actions': ['output:#STEP[2][1]'], 'idle_timeout': '0'}],
# Start VMs
['vnf1', 'start'],
['trafficgen', 'send_traffic', \
{'traffic_type' : 'rfc2544_continuous', \
'bidir' : 'False'}],
['vnf1', 'stop'],
# Clean up
['vswitch', 'dump_flows', 'int_br0'], # STEP 10
['vswitch', 'del_flow', 'int_br0'], # STEP 11
['vswitch', 'del_port', 'int_br0', '#STEP[1][0]'],
['vswitch', 'del_port', 'int_br0', '#STEP[2][0]'],
['vswitch', 'del_port', 'int_br0', '#STEP[3][0]'], # vm1 ports
['vswitch', 'del_port', 'int_br0', '#STEP[4][0]'],
['vswitch', 'del_switch', 'int_br0'],
]
},
To run the test:
./vsperf --conf-file user_settings.py --test-params \
"GUEST_LOOPBACK=['linux_bridge']" --integration ex_pvp_rule_l3da
2.3.6. Forward packets based on UDP port
This examples launches 2 VMs connected in parallel.
Incoming packets will be forwarded to one specific VM depending on the
destination UDP port.
{
"Name": "ex_2pvp_rule_l4dp",
"Description": "2 PVP with flows on L4 Dest Port",
"Deployment": "clean",
"Parameters": {
'TRAFFIC' : {
"multistream": 2,
"stream_type": "L4",
},
},
"TestSteps": [
['vswitch', 'add_switch', 'int_br0'], # STEP 0
['vswitch', 'add_phy_port', 'int_br0'], # STEP 1
['vswitch', 'add_phy_port', 'int_br0'], # STEP 2
['vswitch', 'add_vport', 'int_br0'], # STEP 3 vm1
['vswitch', 'add_vport', 'int_br0'], # STEP 4
['vswitch', 'add_vport', 'int_br0'], # STEP 5 vm2
['vswitch', 'add_vport', 'int_br0'], # STEP 6
# Setup Flows to reply ICMPv6 and similar packets, so to
# avoid flooding internal port with their re-transmissions
['vswitch', 'add_flow', 'int_br0', \
{'priority': '1', 'dl_src': '00:00:00:00:00:01', \
'actions': ['output:#STEP[3][1]'], 'idle_timeout': '0'}],
['vswitch', 'add_flow', 'int_br0', \
{'priority': '1', 'dl_src': '00:00:00:00:00:02', \
'actions': ['output:#STEP[4][1]'], 'idle_timeout': '0'}],
['vswitch', 'add_flow', 'int_br0', \
{'priority': '1', 'dl_src': '00:00:00:00:00:03', \
'actions': ['output:#STEP[5][1]'], 'idle_timeout': '0'}],
['vswitch', 'add_flow', 'int_br0', \
{'priority': '1', 'dl_src': '00:00:00:00:00:04', \
'actions': ['output:#STEP[6][1]'], 'idle_timeout': '0'}],
# Forward UDP packets depending on dest port
['vswitch', 'add_flow', 'int_br0', {'in_port': '#STEP[1][1]', \
'dl_type': '0x0800', 'nw_proto': '17', 'udp_dst': '0', \
'actions': ['output:#STEP[3][1]'], 'idle_timeout': '0'}],
['vswitch', 'add_flow', 'int_br0', {'in_port': '#STEP[1][1]', \
'dl_type': '0x0800', 'nw_proto': '17', 'udp_dst': '1', \
'actions': ['output:#STEP[5][1]'], 'idle_timeout': '0'}],
# Send VM output to phy port #2
['vswitch', 'add_flow', 'int_br0', {'in_port': '#STEP[4][1]', \
'actions': ['output:#STEP[2][1]'], 'idle_timeout': '0'}],
['vswitch', 'add_flow', 'int_br0', {'in_port': '#STEP[6][1]', \
'actions': ['output:#STEP[2][1]'], 'idle_timeout': '0'}],
# Start VMs
['vnf1', 'start'], # STEP 16
['vnf2', 'start'], # STEP 17
['trafficgen', 'send_traffic', \
{'traffic_type' : 'rfc2544_continuous', \
'bidir' : 'False'}],
['vnf1', 'stop'],
['vnf2', 'stop'],
['vswitch', 'dump_flows', 'int_br0'],
# Clean up
['vswitch', 'del_flow', 'int_br0'],
['vswitch', 'del_port', 'int_br0', '#STEP[1][0]'],
['vswitch', 'del_port', 'int_br0', '#STEP[2][0]'],
['vswitch', 'del_port', 'int_br0', '#STEP[3][0]'], # vm1 ports
['vswitch', 'del_port', 'int_br0', '#STEP[4][0]'],
['vswitch', 'del_port', 'int_br0', '#STEP[5][0]'], # vm2 ports
['vswitch', 'del_port', 'int_br0', '#STEP[6][0]'],
['vswitch', 'del_switch', 'int_br0'],
]
},
To run the test:
./vsperf --conf-file user_settings.py --integration ex_2pvp_rule_l4dp
2.3.7. Modification of existing PVVP deployment
This is an example of modification of a standard deployment scenario with additional TestSteps.
Standard PVVP scenario is used to configure a vSwitch and to deploy two VNFs connected
in series. Additional TestSteps will deploy a 3rd VNF and connect it in parallel to
already configured VNFs. Traffic generator is instructed (by Multistream feature) to send
two separate traffic streams. One stream will be sent to the standalone VNF and second
to two chained VNFs.
In case, that test is defined as a performance test, then traffic results will be collected
and available in both csv and rst report files.
{
"Name": "pvvp_pvp_cont",
"Deployment": "pvvp",
"Description": "PVVP and PVP in parallel with Continuous Stream",
"Parameters" : {
"TRAFFIC" : {
"traffic_type" : "rfc2544_continuous",
"multistream": 2,
},
},
"TestSteps": [
['vswitch', 'add_vport', 'br0'],
['vswitch', 'add_vport', 'br0'],
# priority must be higher than default 32768, otherwise flows won't match
['vswitch', 'add_flow', 'br0',
{'in_port': '1', 'actions': ['output:#STEP[-2][1]'], 'idle_timeout': '0', 'dl_type':'0x0800',
'nw_proto':'17', 'tp_dst':'0', 'priority': '33000'}],
['vswitch', 'add_flow', 'br0',
{'in_port': '2', 'actions': ['output:#STEP[-2][1]'], 'idle_timeout': '0', 'dl_type':'0x0800',
'nw_proto':'17', 'tp_dst':'0', 'priority': '33000'}],
['vswitch', 'add_flow', 'br0', {'in_port': '#STEP[-4][1]', 'actions': ['output:1'],
'idle_timeout': '0'}],
['vswitch', 'add_flow', 'br0', {'in_port': '#STEP[-4][1]', 'actions': ['output:2'],
'idle_timeout': '0'}],
['vswitch', 'dump_flows', 'br0'],
['vnf1', 'start'],
]
},
To run the test:
./vsperf --conf-file user_settings.py pvvp_pvp_cont
3. Integration tests
VSPERF includes a set of integration tests defined in conf/integration.
These tests can be run by specifying –integration as a parameter to vsperf.
Current tests in conf/integration include switch functionality and Overlay
tests.
Tests in the conf/integration can be used to test scaling of different switch
configurations by adding steps into the test case.
For the overlay tests VSPERF supports VXLAN, GRE and GENEVE tunneling protocols.
Testing of these protocols is limited to unidirectional traffic and
P2P (Physical to Physical scenarios).
NOTE: The configuration for overlay tests provided in this guide is for
unidirectional traffic only.
3.1. Executing Integration Tests
To execute integration tests VSPERF is run with the integration parameter. To
view the current test list simply execute the following command:
./vsperf --integration --list
The standard tests included are defined inside the
conf/integration/01_testcases.conf file.
3.2. Executing Tunnel encapsulation tests
The VXLAN OVS DPDK encapsulation tests requires IPs, MAC addresses,
bridge names and WHITELIST_NICS for DPDK.
NOTE: Only Ixia traffic generators currently support the execution of the tunnel
encapsulation tests. Support for other traffic generators may come in a future
release.
Default values are already provided. To customize for your environment, override
the following variables in you user_settings.py file:
# Variables defined in conf/integration/02_vswitch.conf
# Tunnel endpoint for Overlay P2P deployment scenario
# used for br0
VTEP_IP1 = '192.168.0.1/24'
# Used as remote_ip in adding OVS tunnel port and
# to set ARP entry in OVS (e.g. tnl/arp/set br-ext 192.168.240.10 02:00:00:00:00:02
VTEP_IP2 = '192.168.240.10'
# Network to use when adding a route for inner frame data
VTEP_IP2_SUBNET = '192.168.240.0/24'
# Bridge names
TUNNEL_INTEGRATION_BRIDGE = 'br0'
TUNNEL_EXTERNAL_BRIDGE = 'br-ext'
# IP of br-ext
TUNNEL_EXTERNAL_BRIDGE_IP = '192.168.240.1/24'
# vxlan|gre|geneve
TUNNEL_TYPE = 'vxlan'
# Variables defined conf/integration/03_traffic.conf
# For OP2P deployment scenario
TRAFFICGEN_PORT1_MAC = '02:00:00:00:00:01'
TRAFFICGEN_PORT2_MAC = '02:00:00:00:00:02'
TRAFFICGEN_PORT1_IP = '1.1.1.1'
TRAFFICGEN_PORT2_IP = '192.168.240.10'
To run VXLAN encapsulation tests:
./vsperf --conf-file user_settings.py --integration \
--test-params 'TUNNEL_TYPE=vxlan' overlay_p2p_tput
To run GRE encapsulation tests:
./vsperf --conf-file user_settings.py --integration \
--test-params 'TUNNEL_TYPE=gre' overlay_p2p_tput
To run GENEVE encapsulation tests:
./vsperf --conf-file user_settings.py --integration \
--test-params 'TUNNEL_TYPE=geneve' overlay_p2p_tput
To run OVS NATIVE tunnel tests (VXLAN/GRE/GENEVE):
- Install the OVS kernel modules
cd src/ovs/ovs
sudo -E make modules_install
- Set the following variables:
VSWITCH = 'OvsVanilla'
# Specify vport_* kernel module to test.
PATHS['vswitch']['OvsVanilla']['src']['modules'] = [
'vport_vxlan',
'vport_gre',
'vport_geneve',
'datapath/linux/openvswitch.ko',
]
NOTE: In case, that Vanilla OVS is installed from binary package, then
please set PATHS['vswitch']['OvsVanilla']['bin']['modules'] instead.
- Run tests:
./vsperf --conf-file user_settings.py --integration \
--test-params 'TUNNEL_TYPE=vxlan' overlay_p2p_tput
3.3. Executing VXLAN decapsulation tests
To run VXLAN decapsulation tests:
- Set the variables used in “Executing Tunnel encapsulation tests”
- Run test:
./vsperf --conf-file user_settings.py --integration overlay_p2p_decap_cont
If you want to use different values for your VXLAN frame, you may set:
VXLAN_FRAME_L3 = {'proto': 'udp',
'packetsize': 64,
'srcip': TRAFFICGEN_PORT1_IP,
'dstip': '192.168.240.1',
}
VXLAN_FRAME_L4 = {'srcport': 4789,
'dstport': 4789,
'vni': VXLAN_VNI,
'inner_srcmac': '01:02:03:04:05:06',
'inner_dstmac': '06:05:04:03:02:01',
'inner_srcip': '192.168.0.10',
'inner_dstip': '192.168.240.9',
'inner_proto': 'udp',
'inner_srcport': 3000,
'inner_dstport': 3001,
}
3.4. Executing GRE decapsulation tests
To run GRE decapsulation tests:
- Set the variables used in “Executing Tunnel encapsulation tests”
- Run test:
./vsperf --conf-file user_settings.py --test-params 'TUNNEL_TYPE=gre' \
--integration overlay_p2p_decap_cont
If you want to use different values for your GRE frame, you may set:
GRE_FRAME_L3 = {'proto': 'gre',
'packetsize': 64,
'srcip': TRAFFICGEN_PORT1_IP,
'dstip': '192.168.240.1',
}
GRE_FRAME_L4 = {'srcport': 0,
'dstport': 0
'inner_srcmac': '01:02:03:04:05:06',
'inner_dstmac': '06:05:04:03:02:01',
'inner_srcip': '192.168.0.10',
'inner_dstip': '192.168.240.9',
'inner_proto': 'udp',
'inner_srcport': 3000,
'inner_dstport': 3001,
}
3.5. Executing GENEVE decapsulation tests
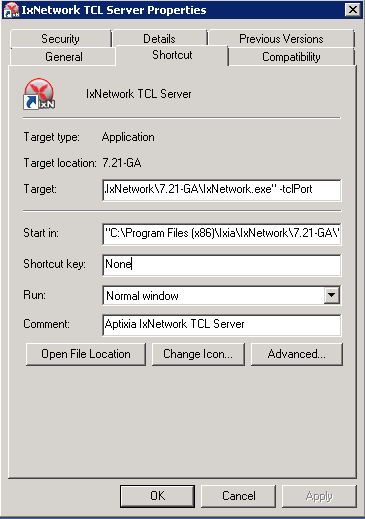
IxNet 7.3X does not have native support of GENEVE protocol. The
template, GeneveIxNetTemplate.xml_ClearText.xml, should be imported
into IxNET for this testcase to work.
To import the template do:
- Run the IxNetwork TCL Server
- Click on the Traffic menu
- Click on the Traffic actions and click Edit Packet Templates
- On the Template editor window, click Import. Select the template
located at
3rd_party/ixia/GeneveIxNetTemplate.xml_ClearText.xml
and click import.
- Restart the TCL Server.
To run GENEVE decapsulation tests:
- Set the variables used in “Executing Tunnel encapsulation tests”
- Run test:
./vsperf --conf-file user_settings.py --test-params 'tunnel_type=geneve' \
--integration overlay_p2p_decap_cont
If you want to use different values for your GENEVE frame, you may set:
GENEVE_FRAME_L3 = {'proto': 'udp',
'packetsize': 64,
'srcip': TRAFFICGEN_PORT1_IP,
'dstip': '192.168.240.1',
}
GENEVE_FRAME_L4 = {'srcport': 6081,
'dstport': 6081,
'geneve_vni': 0,
'inner_srcmac': '01:02:03:04:05:06',
'inner_dstmac': '06:05:04:03:02:01',
'inner_srcip': '192.168.0.10',
'inner_dstip': '192.168.240.9',
'inner_proto': 'udp',
'inner_srcport': 3000,
'inner_dstport': 3001,
}
3.6. Executing Native/Vanilla OVS VXLAN decapsulation tests
To run VXLAN decapsulation tests:
- Set the following variables in your user_settings.py file:
PATHS['vswitch']['OvsVanilla']['src']['modules'] = [
'vport_vxlan',
'datapath/linux/openvswitch.ko',
]
TRAFFICGEN_PORT1_IP = '172.16.1.2'
TRAFFICGEN_PORT2_IP = '192.168.1.11'
VTEP_IP1 = '172.16.1.2/24'
VTEP_IP2 = '192.168.1.1'
VTEP_IP2_SUBNET = '192.168.1.0/24'
TUNNEL_EXTERNAL_BRIDGE_IP = '172.16.1.1/24'
TUNNEL_INT_BRIDGE_IP = '192.168.1.1'
VXLAN_FRAME_L2 = {'srcmac':
'01:02:03:04:05:06',
'dstmac':
'06:05:04:03:02:01',
}
VXLAN_FRAME_L3 = {'proto': 'udp',
'packetsize': 64,
'srcip': TRAFFICGEN_PORT1_IP,
'dstip': '172.16.1.1',
}
VXLAN_FRAME_L4 = {
'srcport': 4789,
'dstport': 4789,
'protocolpad': 'true',
'vni': 99,
'inner_srcmac': '01:02:03:04:05:06',
'inner_dstmac': '06:05:04:03:02:01',
'inner_srcip': '192.168.1.2',
'inner_dstip': TRAFFICGEN_PORT2_IP,
'inner_proto': 'udp',
'inner_srcport': 3000,
'inner_dstport': 3001,
}
NOTE: In case, that Vanilla OVS is installed from binary package, then
please set PATHS['vswitch']['OvsVanilla']['bin']['modules'] instead.
- Run test:
./vsperf --conf-file user_settings.py --integration \
--test-params 'tunnel_type=vxlan' overlay_p2p_decap_cont
3.7. Executing Native/Vanilla OVS GRE decapsulation tests
To run GRE decapsulation tests:
- Set the following variables in your user_settings.py file:
PATHS['vswitch']['OvsVanilla']['src']['modules'] = [
'vport_gre',
'datapath/linux/openvswitch.ko',
]
TRAFFICGEN_PORT1_IP = '172.16.1.2'
TRAFFICGEN_PORT2_IP = '192.168.1.11'
VTEP_IP1 = '172.16.1.2/24'
VTEP_IP2 = '192.168.1.1'
VTEP_IP2_SUBNET = '192.168.1.0/24'
TUNNEL_EXTERNAL_BRIDGE_IP = '172.16.1.1/24'
TUNNEL_INT_BRIDGE_IP = '192.168.1.1'
GRE_FRAME_L2 = {'srcmac':
'01:02:03:04:05:06',
'dstmac':
'06:05:04:03:02:01',
}
GRE_FRAME_L3 = {'proto': 'udp',
'packetsize': 64,
'srcip': TRAFFICGEN_PORT1_IP,
'dstip': '172.16.1.1',
}
GRE_FRAME_L4 = {
'srcport': 4789,
'dstport': 4789,
'protocolpad': 'true',
'inner_srcmac': '01:02:03:04:05:06',
'inner_dstmac': '06:05:04:03:02:01',
'inner_srcip': '192.168.1.2',
'inner_dstip': TRAFFICGEN_PORT2_IP,
'inner_proto': 'udp',
'inner_srcport': 3000,
'inner_dstport': 3001,
}
NOTE: In case, that Vanilla OVS is installed from binary package, then
please set PATHS['vswitch']['OvsVanilla']['bin']['modules'] instead.
- Run test:
./vsperf --conf-file user_settings.py --integration \
--test-params 'tunnel_type=gre' overlay_p2p_decap_cont
3.8. Executing Native/Vanilla OVS GENEVE decapsulation tests
To run GENEVE decapsulation tests:
- Set the following variables in your user_settings.py file:
PATHS['vswitch']['OvsVanilla']['src']['modules'] = [
'vport_geneve',
'datapath/linux/openvswitch.ko',
]
TRAFFICGEN_PORT1_IP = '172.16.1.2'
TRAFFICGEN_PORT2_IP = '192.168.1.11'
VTEP_IP1 = '172.16.1.2/24'
VTEP_IP2 = '192.168.1.1'
VTEP_IP2_SUBNET = '192.168.1.0/24'
TUNNEL_EXTERNAL_BRIDGE_IP = '172.16.1.1/24'
TUNNEL_INT_BRIDGE_IP = '192.168.1.1'
GENEVE_FRAME_L2 = {'srcmac':
'01:02:03:04:05:06',
'dstmac':
'06:05:04:03:02:01',
}
GENEVE_FRAME_L3 = {'proto': 'udp',
'packetsize': 64,
'srcip': TRAFFICGEN_PORT1_IP,
'dstip': '172.16.1.1',
}
GENEVE_FRAME_L4 = {'srcport': 6081,
'dstport': 6081,
'protocolpad': 'true',
'geneve_vni': 0,
'inner_srcmac': '01:02:03:04:05:06',
'inner_dstmac': '06:05:04:03:02:01',
'inner_srcip': '192.168.1.2',
'inner_dstip': TRAFFICGEN_PORT2_IP,
'inner_proto': 'udp',
'inner_srcport': 3000,
'inner_dstport': 3001,
}
NOTE: In case, that Vanilla OVS is installed from binary package, then
please set PATHS['vswitch']['OvsVanilla']['bin']['modules'] instead.
- Run test:
./vsperf --conf-file user_settings.py --integration \
--test-params 'tunnel_type=geneve' overlay_p2p_decap_cont
3.9. Executing Tunnel encapsulation+decapsulation tests
The OVS DPDK encapsulation/decapsulation tests requires IPs, MAC addresses,
bridge names and WHITELIST_NICS for DPDK.
The test cases can test the tunneling encap and decap without using any ingress
overlay traffic as compared to above test cases. To achieve this the OVS is
configured to perform encap and decap in a series on the same traffic stream as
given below.
TRAFFIC-IN –> [ENCAP] –> [MOD-PKT] –> [DECAP] –> TRAFFIC-OUT
Default values are already provided. To customize for your environment, override
the following variables in you user_settings.py file:
# Variables defined in conf/integration/02_vswitch.conf
# Bridge names
TUNNEL_EXTERNAL_BRIDGE1 = 'br-phy1'
TUNNEL_EXTERNAL_BRIDGE2 = 'br-phy2'
TUNNEL_MODIFY_BRIDGE1 = 'br-mod1'
TUNNEL_MODIFY_BRIDGE2 = 'br-mod2'
# IP of br-mod1
TUNNEL_MODIFY_BRIDGE_IP1 = '10.0.0.1/24'
# Mac of br-mod1
TUNNEL_MODIFY_BRIDGE_MAC1 = '00:00:10:00:00:01'
# IP of br-mod2
TUNNEL_MODIFY_BRIDGE_IP2 = '20.0.0.1/24'
#Mac of br-mod2
TUNNEL_MODIFY_BRIDGE_MAC2 = '00:00:20:00:00:01'
# vxlan|gre|geneve, Only VXLAN is supported for now.
TUNNEL_TYPE = 'vxlan'
To run VXLAN encapsulation+decapsulation tests:
./vsperf --conf-file user_settings.py --integration \
overlay_p2p_mod_tput















{kind=link}
{kind=link}