Scenario Lifecycle¶
Contents:
Note: This document is still work in progress.
1. Overview¶
1.1. Problem Statement:¶
OPNFV provides the NFV reference platform in different variants, using different upstream open source projects. In many cases this includes also different upstream projects providing similar or overlapping functionality.
OPNFV introduces scenarios to define various combinations of components from upstream projects or configuration options for these components.
The number of such scenarios has increased over time, so it is necessary to clearly define how to handle the scenarios.
1.2. Introduction:¶
Some OPNFV scenarios have an experimental nature, since they introduce new technologies that are not yet mature enough to provide a stable release. Nevertheless there also needs to be a way to provide the user with the opportunity to try these new features in an OPNFV release context.
Other scenarios are used to provide stable environments for users that wish to build products or live deployments on them.
OPNFV scenario lifecycle process will support this by defining two types of scenarios:
- Generic scenarios cover a stable set of common features provided by different components and target long-term usage.
- Specific scenarios are needed during development to introduce new upstream components or new features. They are intended to merge with other specific scenarios and bring their features into at least one generic scenario.
OPNFV scenarios are deployed using one of the installer tools. A scenario can be deployed by multiple installers and the result will look very similar but different. The capabilities provided by the deployments should be identical. Results of functional tests should be the same, independent of the installer that had been used. Performance or other behavioral aspects could be different. The scenario lifecycle process will also define how to document which installer can be used for a scenario and how the CI process can trigger automatic deployment for a scenario via one of the supported installers.
When a developer decides to define a new scenario, he typically will take one of the existing scenarios and does some changes, such as:
- add additional components
- change a deploy-time configuration
- use a component in a more experimental version
In this case the already existing scenario is called a “parent” and the new scenario a “child”.
Typically parent scenarios are generic scenarios, but this is not mandated. In most times the child scenario will develop the new functionality over some time and then try to merge its configuration back to the parent. But in other cases, the child will introduce a technology that cannot easily be combined with the parent. For this case this document will define how a new generic scenario can be created.
Many OPNFV scenarios can be deployed in a HA (high availability) or non-HA configuration. HA configurations deploy some components according to a redundancy model, as the components support. In these cases multiple deployment options are defined for the same scenario.
Deployment options will also be used if the same scenario can be deployed on multiple types of hardware, i.e. Intel and ARM.
Every scenario will be described in a scenario descriptor yaml file. This file shall contain all the necessary information for different users, such as the installers (which components to deploy etc.), the ci process (to find the right resources), the test projects (to select correct test cases), etc.
In early OPNFV releases, scenarios covered components of the infrastructure, that is NFVI and VIM. With the introduction of MANO, an additional dimension for scenarios is needed. The same MANO components need to be used together with each of the infrastructure scenarios. Thus MANO scenarios will define the MANO components and a list of infrastructure scenarios to work with. Please note that MANO scenarios follow the same lifecycle and rules for generic and specific scenarios like the infrastructure scenarios.
2. Generic Scenarios¶
Generic scenarios provide a stable environment for users who want to base their products on them.
- Generic scenarios provide a basic combination of upstream components together with the superset of possible mature features that can be deployed on them.
- Generic scenarios should be supported by all installers.
- All generic scenarios in a release should have the same common major versions of the included upstream components. These upstream versions can then be seen as the upstream versions for the release. E.g. that way we can say: “OPNFV xxx contains OpenStack abc, ODL def, ONOS ghi, OVS jkl“. But most installers cannot directly reference any upstream version. This may lead to minor differences. Nevertheless features and test cases require all installers using the same major versions.
- Generic scenarios should use stable sources and lock the versions before the release by either pointing to a tag or sha1. According to the LF badging program it should be possible to reproduce the release from source again. Thus the upstream repos should be in safe locations. Also only tagged source versions should be used for the release, so the release can be reproduced identically for different purposes such as reproducing a baug reported by users and issuing the fix appropriately, even after the upstream project has applied patches. .. Editors note: There is discussion ongoing in INFRA and SEC working groups how .. to realize this. Thus the description is still a bit vague. Details will be .. added later either here or in some INFRA document.
- Generic scenarios should be stable and mature. Therefore they will be tested more thoroughly and run special release testing so a high level of stability can be provided.
- Generic scenarios will live through many OPNFV releases.
- More resources will be allocated to maintaining generic scenarios and they will have priority for CI resources. .. Editors note: Discussion ongoing in INFRA about toolchain issues.
Note: in some cases it might be difficult for an installer to support all generic scenarios immediately. In this case an exception can be defined, but the installer has to provide a plan how to achieve support for all generic scenarios.
Note: in some cases, upstream projects don‘t have proper CI process with tagged stable versions. Also some installers‘ way of working doesn‘t allow selecting the repo and tag. Thus a stepwise approach will be necessary to fulfill this requirement.
3. Specific Scenarios¶
Specific scenarios are used for OPNFV development and help to isolate a path of development.
- Specific scenarios typically focus on a feature or topic.
- Specific scenarios allow to advance in development for their main feature without de-stabilizing other features.
- Specific scenarios provide additional flexibility in their handling to allow the development be agile.
- Specific scenarios can use new version of their main upstream component or even apply midstream patches during OPNFV deployment, i.e. the deployable artifact is created via cross community CI or even only in OPNFV and not upstream.
- Specific scenarios should have a limited life time. After a few releases, the feature development should have matured and the feature made available different configurations if possible. Typically the scenario then should be merged with other scenarios, best with generic scenarios.
- Normally specific scenarios will be released within the major OPNFV releases. But they don’t need to fulfill maturity requirements (stable upstream versions and repos, stability testing), and can deviate in the used upstream versions.
- In exceptional cases we might release a specific scenario independently, in case there is a need. Thus specific scenarios provide a way to a more DevOps-like process.
- Specific scenarios will likely have a shorter support period after release as they are of interest to a smaller user community vs generic scenarios.
- They will be granted less CI resources than generic scenarios, e.g. for periodic CI jobs.
- We may need to prioritize resources post-release for maintenance / regression testing.
4. Parent - Child Relations¶
In many cases, development adds a feature to an existing scenario by adding additional components. This is called creating a child scenario from a parent.
- Parent scenarios typically are more stable than children.
- Children should plan to merge their feature back to the parent.
- Merge back will often add components to the parent.

- Child scenarios can be part of releases.
- Child scenarios should merge back to their parent after 2 releases.
- If a child scenario lives through several releases, it might be desirable to “rebase/cherrypick” a child scenario to follow changes in the parent scenario.
- Child scenarios typically support a smaller number of deployment options than their parent
Child scenarios are specific scenarios. Parent scenarios can be generic or specific scenarios.
Child scenarios can be created any time. If they want to join a release, they have to be created before MS0 of that release.
4.1. Siblings¶
In some cases it could make more sense to create a sibling rather than a child (e.g. if expected that merging back to parent will be difficult). In other words, the content of a child scenario will be incompatible with content of the parent scenario. In that case, the child scenario should rather become a new branch instead of merging back to the parent.

Typically the sibling uses alternate components/solutions than the parent – in long term it might evolve into a new generic scenario, that is a new branch in the scenario tree.
Creation of the sibling shall not be gated. It should be covered in the scope of an approved project, so there cannot be too big surprises.
But at a certain time the new scenario will want to change its status from a specific scenario to a generic scenario. This move will need TSC approval. For the application, the scenario owner shall demonstrate that the scenario fulfills the requirements of a generic scenario (see later).
Examples: SDN controller options, Container technologies, data plane solutions, MANO solutions.
Please note that from time to time, the TSC will need to review the set of generic scenarios and “branches” in the scenario tree.
5. Creating Scenarios¶
5.1. Purpose¶
A new scenario needs to be created, when a new combination of upstream components or features shall be supported, that cannot be provided with the existing scenarios in parallel to their existing features.
Typically new scenarios are created as children of existing scenarios.
In some cases an upstream implementation can be replaced by a different solution. The most obvious example here is the SDN controller. In the first OPNFV release, only ODL was supported. Later ONOS and OpenContrail were added, thus creating new scenarios.
In most cases, only one of the SDN controllers is needed, thus OPNFV will support the different SDN controllers by different scenarios. This support will be long- term, so there will be multiple generic scenarios for these options.
Another usecase is feature incompatibilities. For instance, OVS and FD.io cannot be combined today. Therefore we need different scenarios for them. If it is expected that such an incompatibility is not solved for longer time, there can be even separate generic scenarios for these options.
The overlap between scenarios should only be allowed where they add components that cannot be integrated in a single deployment.
If scenario A completely covers scenario B, support of scenario B will be only provided as long as isolation of development risks is necessary. However, there might be cases where somebody wants to use scenario B still as a parent for specific scenarios.
This is especially the case for generic scenarios, since they need more CI and testing resources. Therefore a gating process will be introduced for generic scenarios.
5.2. Creating Generic Scenarios¶
Generic scenarios provide stable and mature deployments of an OPNFV release. Therefore it is important to have generic scenarios in place that provide the main capabilities needed for NFV environments. On the other hand the number of generic scenarios needs to be limited because of resources.
- Creation of a new generic scenario needs TSC consensus.
- Typically the generic scenario is created by promoting an existing specific scenario. Thus the only the additional information needs to be provided.
- The scenario owner needs to verify that the scenario fulfills the above requirements.
- Since specific scenarios typically are owned by the project who have initiated it, and generic scenarios provide a much broader set of features, in many cases a change of owner is appropriate. In most cases it will be appropriate to assign a testing expert as scenario owner.
5.3. Creating Specific Scenarios¶
As already stated, typically specific scenarios are created as children of existing scenarios. The parent can be a generic or a specific scenario.
Creation of specific scenarios shall be very easy and can be done any time. However, support might be low priority during a final release preparation, e.g. after a MS6.
- The PTL of the project developing the feature(s) or integrating a component etc can request the scenario (tbd from whom: CI or release manager, no need for TSC)
- The PTL shall provide some justification why a new scenario is needed. It will be approptiate to discuss that justification in the weekly technical discussion meeting.
- The PTL should have prepared that by finding support from one of the installers.
- The PTL should explain from which “parent scenario” (see below) the work will start, and what are the planned additions.
- The PTL shall assign a unique name. Naming rules will be set by TSC.
- The PTL shall provide some time schedule plans when the scenario wants to join a release, when he expects the scenario merge to other scenarios, and he expects the features may be made available in generic scenarios. A scenario can join a release at the MS0 after its creation. It should join a release latest on the next MS0 6 month after its creation (that is it should skip only one release) and merge to its parent maximum 2 releases later. .. Editors note: “2 releases” is rather strict maybe refine?
- The PTL should explain the infrastructure requirements and clarify that sufficient resources are available for the scenario.
- The PTL shall assign a scenario owner.
- The scenario owner shall maintain the scenario descriptor file according to the template.
- The scenario owner shall initiate the scenario be integrated in CI or releases.
- When the scenario joins a release this needs to be done in time for the relevant milestones.
6. Deployment Options¶
6.1. What are deployment options?¶
During the analysis of scenario definitions in Colorado and Danube releases, it became visible, that HA and NOHA deployment of otherwise identical scenarios shouldn’t be called different scenarios.
This understanding leads to the definition of another kind of attributes in scenario definitions. Many scenarios can be deployed in different ways:
- HA configuration of OpenStack modules (that is redundancy using multiple controllers running OpenStack services) versus NOHA with only a single controller running a single instance of each OpenStack service
- Some scenarios can be deployed on intel and on ARM hardware.
- We can see the installation tools in the same way. Independent of the installer that was used for the deployment of a scenario, the same functionality will be provided and we can run the same testcases.
Please note that a scenario can support multiple deployment options. And a scenario definition must specify at least one option of each type.
In future there will be more deployment options, e.g. redundancy models or other clustering options of SDN controllers, or upscaling compute or control nodes.
CI Pipeline needs to test all configuration options of a scenario.
- Development cycles (verify-jobs, daily, weekly) don‘t need to run all options each time
- Release testing must cover all those combinations of configuration options that will be part of the release. Typically the HA configurations are released on bare metal with the allowed hardware options and all installers that can deploy those. Release of an NOHA option should be an exception, e.g. for a scenarios that are not mature yet.
- Virtual deployments are not mentioned here. All scenarios should allow virtual deployment where applicable. But in release testing, bare metal deployment will be necessary. CI will use virtual deployments as much as appropriate for resource reasons.
6.2. Deployment options or new scenarios¶
In general we can say that a different scenario is needed when the set of components is changed (or in some cases a general deploy-time configuration of a component). If we deploy the same components in a different way, we can define this via deployment options.
Examples
- Deploying different SDN controller or data plane (OVS/FD.IO) requires different scenario.
- HA/NOHA will deploy the same components on different number of nodes, so it is a deployment option.
- Different hardware types should not lead to new scenarios. Typically the same scenario can be deployed on multiple hardware.
6.3. HA and NOHA¶
Both, HA and NOHA options of a scenario are important.
- HA deployment is important to be released in major OPNFV releases, because telco deployments typically have strong requirements on availability.
- NOHA deployments require less resources and are sufficient for many use cases. For instance sandbox testing can be done easier and also automatic verification in the CI pipeline can make use of it.
- Generic scenarios shall support the HA and NOHA option.
- Specific scenarios can focus on the NOHA option if their features are independent from the controller redundancy. But before merging with generic scenarios, they should provide both options.
6.4. Hardware types¶
In its first releases, OPNFV could be deployed on Intel hardware only. Later, support for ARM hardware was added and now 5 scenarios can already be deployed on both.
6.5. Virtual deployment¶
Many, but not all scenarios can be deployed on virtual PODs. Therefore the scenario definition shall specify whether virtual deployment is possible.
Typically a virtual HA deployment shall look very much the same as a bare-metal HA deployment, that is the distribution of modules on nodes/VMs is similar. But there might be cases where there are differences. Thus, the scenario specification needs to provide the data for each separately.
6.6. Deployment tools¶
Deployment tools (installers) are in a very similar relation to the scenarios. Each scenario can be deployed by one or more installer. Thus we can specify the installers for a scenario as a deployment option.
However, the installers need additional detailed information for the deployment. Every installer may not support the same HA, hardware, virtualization options, or same distribution of modules. Each deployment may look slightly different per installer.
The scenario definition needs to provide such information in a way it can be easily consumed by the installers.
6.7. Other deployment options¶
This set of deployment options is based on what is required by Danube scenarios. Future releases will most likely introduce additional deployment options.
7. MANO Scenarios¶
Since OPNFV organizes all deployments using scenarios, also MANO components need to be covered by scenarios.
On the other side all NFVI/VIM level scenarios need to be orchestrated using a set of components from the NFVO and VNFM layer.
The idea here is therefore to specify for a MANO scenario:
- The MANO components to deploy
- A list of supported NFVI/VIM level scenarios that can be orchestrated using this MANO scenario.
The MANO test cases will define the VNFs to use.
MANO scenarios will have more work to do if they require new nodes to be deployed on. They should include this aspect in their resource planning/requests and contact Infra/Pharos in case that a change of the Pharos spec is needed and new PODs need to be made available based on the amended spec.
More details need to be investigated as we gain experience with the MANO scenarios
8. Current Status¶
tdb: this chapter will summarize the scenario analysis.
8.1. Arno¶
In Arno release, the scenario concept was not created yet. Looking back, we can say we had one scenario with OpenStack, ODL and KVM, that could be deployed in two ways, by the two installers available in Arno.
8.2. Brahmaputra¶
tbd
8.3. Colorado¶
tbd
8.4. Danube¶
tbd: Analysis of the 58 scenarios The analysis can be found in the slides at https://wiki.opnfv.org/display/INF/Scenario+Consolidation and will be explain with some text here. The text will also use the diagrams from the slides, e.g. show a scenario tree:
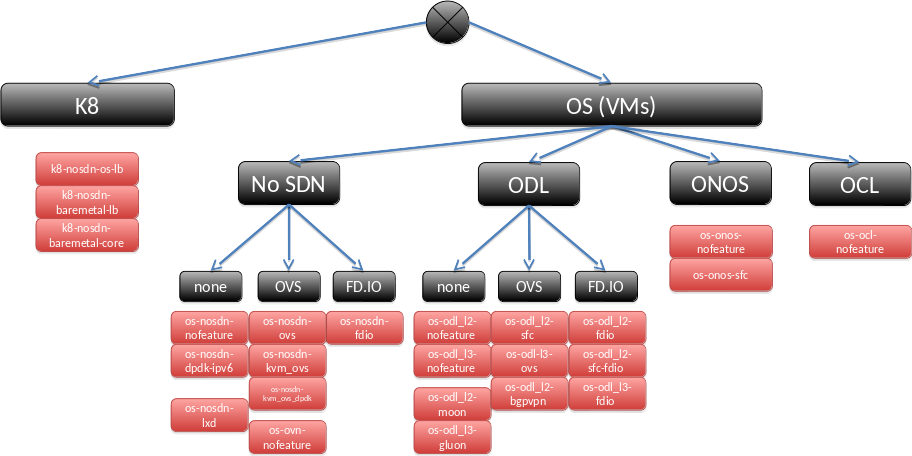
and an idea about possible generic scenarios:
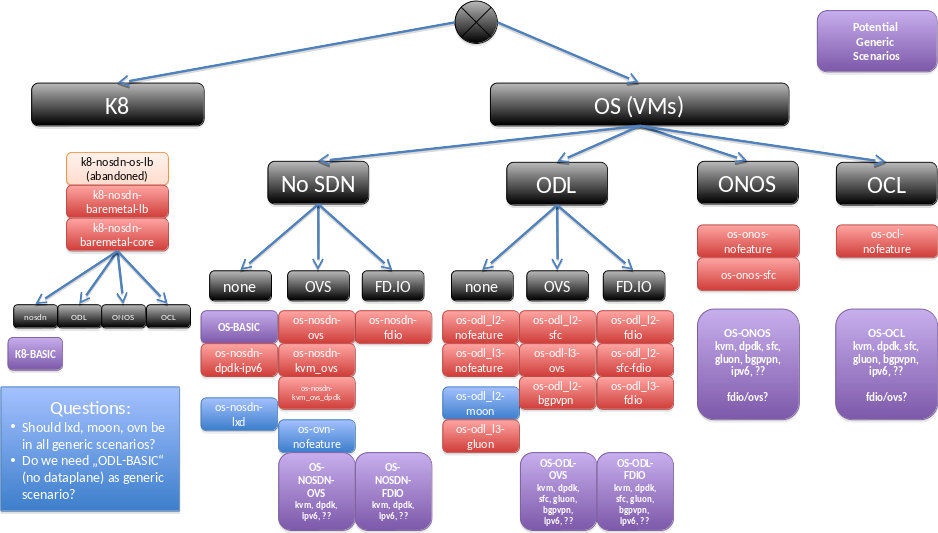
as well as possible ways to reach this.
9. Scenario Descriptor Files¶
9.1. What are Scenario Descriptor Files?¶
Every scenario is described in its own descriptor file. The scenario descriptor file will be used by several parties:
Installer tools will read from it the list of components to be installed and the configuration (e.g. deployment options and necessary details) to use.
The dynamic CI process will read from it the prerequisites of the scenario to select the resource that has the needed capabilities for the deployment. It will also select the installer from the list of supported installers and the other deployment options as supported in their combination.
The dynamic CI process will provide the installers with the deployment option to use for a particular deployment.
The scenario owner needs to provide the descriptor file.
When compiling it the scenario owner typically needs to work together with the installers, so the installers will support the required components and options.
The testing framework can read from the scenario descriptor file necessary information to know which features can be tested on the scenario.
The scenario descriptor file will also contain some maintenance information
9.2. Structure of the file¶
The scenario descriptor file is a yaml file. The syntax will allow to specify additional descriptor files, to make it better readable or structure common configurations across multiple scenarios.
The file has following main sections:
- metadata (owner, history, description)
- list of components (names, versions, submodules)
- deployment options (HA/NOHA, hardware&virtualization, installers, including possible combinations and necessary details)
- other prerequisites (e.g. memory requirement more than pharos spec)
- list of features to be tested
More information to be provided in next version of this document. The file will be defined based on the installer-specific files for scenario specification used by the 4 installers in Danube release. Thus it will be made sure that the information needed by the installers will be covered.
All scenario files will be stored in a central repo, e.g. Octopus. There will also be a commented template to help create scenario descriptor files.
9.3. Metadata¶
In Danube timeframe only Fuel installer has some metadata in the descriptor file. The new template contains:
Unique name
This is a free name, there is a recommendation to take fish for names, matching OPNFV release naming with rivers.
A free text title
This should be a short descriptive text telling the main purpose
A version number for the descriptor file
Three digits, separated with dots, as used by Fuel in Danube
Creation date
Comment
The file should contain a clear description of the purpose of the scenario, including the main benefits and major features. If applicable, the parent scenario should be mentioned.
First OPNFV version to use the scenario
Author/Owner
A list of additional contact persons, e.g. from installers or major components
9.4. Components¶
In this section all components are listed together with their version. For some components in addtion submodules can be listed.
More details will be added.
9.5. Deployment options¶
This section will list the supported deployment options. In each category at least one option must be supported.
hardware (cpu) types (intel or ARM)
Virtualization (bare-metal or vPOD)
availability (HA or NOHA)
This subsection needs to specify also what does an HA deployment need, e.g.:
availability:
- type: HA
nodes:
- name: host1
roles:
- openstack-controller
- odl
- ceph-adm
- ceph-mon
- name: host2
roles:
- openstack-controller
- odl
- ceph-adm
- ceph-mon
- name: host3
roles:
- openstack-controller
- odl
- ceph-adm
- ceph-mon
- name: host4
- openstack-compute
- ceph-osd
- name: host5
- openstack-compute
- ceph-osd
- type: NOHA
hosts:
- name: host1
roles:
- openstack-controller
- odl
- ceph-adm
- ceph-mon
- name: host2
- openstack-compute
- ceph-osd
- name: host3
- openstack-compute
- ceph-osd
deployment tool (apex, compass, fuel, daisy, joid)
In the section for each deployment tool, the combinations of the first three options have to be listed, e.g.:
deployment-tools:
- type: fuel
cpu: intel
pod: baremetal
availability: HA
- type: fuel
cpu: intel
pod: virtual
availability: HA
- type: fuel
cpu: intel
pod: virtual
availability: NOHA
Please note that this allows easy definition of other availability options including scaling and redundant configuration of SDN controllers.
9.6. Prerequisites¶
This section will list additional prerequisites. Currently there is only one case where a scenario has additional prerequisites to the Pharos spec. E.g. a component could requires more RAM on the nodes than defined in Pharos spec. In general it should be preferred to issue such requirements to pharos using the pharos change request process, but in some cases in might be better to specify additional prerequisites.
Another use case for these prerequisites will be usage of specilized hardware, e.g. for acceleration. This needs further study.
The section can be empty or omitted.
9.7. Testcases¶
This section will provide information for functest and yardstick to decide on the proper test cases for the scenario.
More details will be added.