Barometer¶
| Project: | |||||
|---|---|---|---|---|---|
| Authors: | Maryam Tahhan <maryam.tahhan@intel.com> |
||||
| History: |
|
Barometer is the project that renames Software Fastpath service Quality Metrics (SFQM) and updates its scope which was networking centric.
The goal of SFQM was to develop the utilities and libraries in DPDK to support:
- Measuring Telco Traffic and Performance KPIs. Including:
- Packet Delay Variation (by enabling TX and RX time stamping).
- Packet loss (by exposing extended NIC stats).
- Performance Monitoring of the DPDK interfaces (by exposing extended NIC stats + collectd Plugin).
- Detecting and reporting violations that can be consumed by VNFs and higher level management systems (through DPDK Keep Alive).
With Barometer the scope is extended to monitoring the NFVI. The ability to monitor the Network Function Virtualization Infrastructure (NFVI) where VNFs are in operation will be a key part of Service Assurance within an NFV environment, in order to enforce SLAs or to detect violations, faults or degradation in the performance of NFVI resources so that events and relevant metrics are reported to higher level fault management systems. If physical appliances are going to be replaced by virtualized appliances the service levels, manageability and service assurance needs to remain consistent or improve on what is available today. As such, the NFVI needs to support the ability to monitor:
- Traffic monitoring and performance monitoring of the components that provide networking functionality to the VNF, including: physical interfaces, virtual switch interfaces and flows, as well as the virtual interfaces themselves and their status, etc.
- Platform monitoring including: CPU, memory, load, cache, themals, fan speeds, voltages and machine check exceptions, etc.
All of the statistics and events gathered must be collected in-service and must be capable of being reported by standard Telco mechanisms (e.g. SNMP), for potential enforcement or correction actions. In addition, this information could be fed to analytics systems to enable failure prediction, and can also be used for intelligent workload placement.
All developed features will be upstreamed to Open Source projects relevant to telemetry such as collectd, and relevant Openstack projects.
OPNFV Barometer configuration Guide¶
Barometer Configuration Guide¶
This document provides guidelines on how to install and configure Barometer with Apex. The deployment script installs and enables a series of collectd plugins on the compute node(s), which collect and dispatch specific metrics and events from the platform.
Pre-configuration activities¶
Deploying the Barometer components in Apex is done through the deploy-opnfv command by selecting
a scenario-file which contains the barometer: true option. These files are located on the
Jump Host in the /etc/opnfv-apex/ folder. Two scenarios are pre-defined to include Barometer,
and they are: os-nosdn-bar-ha.yaml and os-nosdn-bar-noha.yaml.
$ cd /etc/opnfv-apex
$ opnfv-deploy -d os-nosdn-bar-ha.yaml -n network_settings.yaml -i inventory.yaml –- debug
Hardware configuration¶
There’s no specific Hardware configuration required. However, the intel_rdt plugin works
only on platforms with Intel CPUs.
Feature configuration¶
All Barometer plugins are automatically deployed on all compute nodes. There is no option to selectively install only a subset of plugins. Any custom disabling or configuration must be done directly on the compute node(s) after the deployment is completed.
Upgrading the plugins¶
The Barometer components are built-in in the Apex ISO image, and respectively the Apex RPMs. There is no simple way to update only the Barometer plugins in an existing deployment.
Barometer post installation procedures¶
This document describes briefly the methods of validating the Barometer installation.
Automated post installation activities¶
The Barometer test-suite in Functest is called barometercollectd and is part of the Features
tier. Running these tests is done automatically by the OPNFV deployment pipeline on the supported
scenarios. The testing consists of basic verifications that each plugin is functional per their
default configurations. Inside the Functest container, the detailed results can be found in the
/home/opnfv/functest/results/barometercollectd.log.
Barometer post configuration procedures¶
The functionality for each plugin (such as enabling/disabling and configuring its capabilities)
is controlled as described in the User Guide through their individual .conf file located in
the /etc/collectd/collectd.conf.d/ folder on the compute node(s). In order for any changes to
take effect, the collectd service must be stopped and then started again.
Platform components validation¶
The following steps describe how to perform a simple “manual” testing of the Barometer components:
Connect to any compute node and ensure that the collectd service is running. The log file
collectd.logshould contain no errors and should indicate that each plugin was successfully loaded. For example, from the Jump Host:$ opnfv-util overcloud compute0 $ ls /etc/collectd/collectd.conf.d/ $ systemctl status collectd $ vi /opt/stack/collectd.log
The following plugings should be found loaded: aodh, gnocchi, hugepages, intel_rdt, mcelog, ovs_events, ovs_stats, snmp, virt
On the compute node, induce an event monitored by the plugins; e.g. a corrected memory error:
$ git clone https://git.kernel.org/pub/scm/utils/cpu/mce/mce-inject.git $ cd mce-inject $ make $ modprobe mce-inject
Modify the test/corrected script to include the following:
CPU 0 BANK 0 STATUS 0xcc00008000010090 ADDR 0x0010FFFFFFF
Inject the error:
$ ./mce-inject < test/corrected
Connect to the controller and query the monitoring services. Make sure the overcloudrc.v3 file has been copied to the controller (from the undercloud VM or from the Jump Host) in order to be able to authenticate for OpenStack services.
$ opnfv-util overcloud controller0 $ su $ source overcloudrc.v3 $ gnocchi metric list $ aodh alarm list
The output for the gnocchi and aodh queries should be similar to the excerpts below:
+--------------------------------------+---------------------+------------------------------------------------------------------------------------------------------------+-----------+-------------+ | id | archive_policy/name | name | unit | resource_id | +--------------------------------------+---------------------+------------------------------------------------------------------------------------------------------------+-----------+-------------+ [...] | 0550d7c1-384f-4129-83bc-03321b6ba157 | high | overcloud-novacompute-0.jf.intel.com-hugepages-mm-2048Kb@vmpage_number.free | Pages | None | | 0cf9f871-0473-4059-9497-1fea96e5d83a | high | overcloud-novacompute-0.jf.intel.com-hugepages-node0-2048Kb@vmpage_number.free | Pages | None | | 0d56472e-99d2-4a64-8652-81b990cd177a | high | overcloud-novacompute-0.jf.intel.com-hugepages-node1-1048576Kb@vmpage_number.used | Pages | None | | 0ed71a49-6913-4e57-a475-d30ca2e8c3d2 | high | overcloud-novacompute-0.jf.intel.com-hugepages-mm-1048576Kb@vmpage_number.used | Pages | None | | 11c7be53-b2c1-4c0e-bad7-3152d82c6503 | high | overcloud-novacompute-0.jf.intel.com-mcelog- | None | None | | | | SOCKET_0_CHANNEL_any_DIMM_any@errors.uncorrected_memory_errors_in_24h | | | | 120752d4-385e-4153-aed8-458598a2a0e0 | high | overcloud-novacompute-0.jf.intel.com-cpu-24@cpu.interrupt | jiffies | None | | 1213161e-472e-4e1b-9e56-5c6ad1647c69 | high | overcloud-novacompute-0.jf.intel.com-cpu-6@cpu.softirq | jiffies | None | [...] +--------------------------------------+-------+------------------------------------------------------------------+-------+----------+---------+ | alarm_id | type | name | state | severity | enabled | +--------------------------------------+-------+------------------------------------------------------------------+-------+----------+---------+ | fbd06539-45dd-42c5-a991-5c5dbf679730 | event | gauge.memory_erros(overcloud-novacompute-0.jf.intel.com-mcelog) | ok | moderate | True | | d73251a5-1c4e-4f16-bd3d-377dd1e8cdbe | event | gauge.mcelog_status(overcloud-novacompute-0.jf.intel.com-mcelog) | ok | moderate | True | [...]
OPNFV Barometer Scenarios¶
1. OPNFV os-nosdn-bar-ha overview and description¶
This document provides details of the scenario for Euphrates release of Barometer.
1.1. Introduction¶
This scenario has the features from the Barometer project. Collectd (a telemetry agent) is installed on compute nodes so that their statistics, events and alarming services can be relayed to Gnoochi and Aodh. These are the first steps in paving the way for Platform (NFVI) Monitoring in OPNFV.
1.2. Scenario components and composition¶
This scenario deploys the High Availability OPNFV Cloud based on the
configurations provided in os-nosdn-bar-ha.yaml.
This yaml file contains configurations and is passed as an
argument to overcloud-deploy-function.sh script.
This scenario deploys multiple nodes: 3 Controllers, 2 Computes.
Collectd is installed on compute nodes and Openstack services runs on the controller nodes.
os-nosdn-bar-ha scenario is successful when all the nodes are accessible, up and running. Also, verify if plugins/services are communicating with Gnocchi and Aodh on the controller nodes.
1.3. Scenario usage overview¶
After installation, plugins will be able to read/write the stats on/from the controller node. A detailed list of supported plugins along with their sample configuration can be found in the userguide.
1. OPNFV os-nosdn-bar-noha overview and description¶
This document provides details of the scenario for Euphrates release of Barometer.
1.1. Introduction¶
This scenario has the features from the Barometer project. Collectd (a telemetry agent) is installed on compute nodes so that their statistics, events and alarming services can be relayed to Gnoochi and Aodh. These are the first steps in paving the way for Platform (NFVI) Monitoring in OPNFV.
1.2. Scenario components and composition¶
This scenario deploys the High Availability OPNFV Cloud based on the
configurations provided in os-nosdn-bar-noha.yaml.
This yaml file contains configurations and is passed as an
argument to overcloud-deploy-function.sh script.
This scenario deploys multiple nodes: 1 Controller, 2 Computes.
Collectd is installed on compute nodes and Openstack services runs on the controller node.
os-nosdn-bar-noha scenario is successful when all the nodes are accessible, up and running. Also, verify if plugins/services are communicating with Gnocchi and Aodh on the controller nodes.
1.3. Scenario usage overview¶
After installation, plugins will be able to read/write the stats on/from the controller node. A detailed list of supported plugins along with their sample configuration can be found in the userguide.
OPNFV Barometer User Guide¶
OPNFV Barometer User Guide¶
Barometer collectd plugins description¶
Collectd is a daemon which collects system performance statistics periodically and provides a variety of mechanisms to publish the collected metrics. It supports more than 90 different input and output plugins. Input plugins retrieve metrics and publish them to the collectd deamon, while output plugins publish the data they receive to an end point. collectd also has infrastructure to support thresholding and notification.
Barometer has enabled the following collectd plugins:
- dpdkstat plugin: A read plugin that retrieves stats from the DPDK extended NIC stats API.
- dpdkevents plugin: A read plugin that retrieves DPDK link status and DPDK forwarding cores liveliness status (DPDK Keep Alive).
- gnocchi plugin: A write plugin that pushes the retrieved stats to Gnocchi. It’s capable of pushing any stats read through collectd to Gnocchi, not just the DPDK stats.
- aodh plugin: A notification plugin that pushes events to Aodh, and creates/updates alarms appropriately.
- hugepages plugin: A read plugin that retrieves the number of available and free hugepages on a platform as well as what is available in terms of hugepages per socket.
- Open vSwitch events Plugin: A read plugin that retrieves events from OVS.
- Open vSwitch stats Plugin: A read plugin that retrieves flow and interface stats from OVS.
- mcelog plugin: A read plugin that uses mcelog client protocol to check for memory Machine Check Exceptions and sends the stats for reported exceptions.
- PMU plugin: A read plugin that provides performance counters data on Intel CPUs using Linux perf interface.
- RDT plugin: A read plugin that provides the last level cache utilization and memory bandwidth utilization.
- virt: A read plugin that uses virtualization API libvirt to gather statistics about virtualized guests on a system directly from the hypervisor, without a need to install collectd instance on the guest.
- SNMP Agent: A write plugin that will act as a AgentX subagent that receives and handles queries from SNMP master agent and returns the data collected by read plugins. The SNMP Agent plugin handles requests only for OIDs specified in configuration file. To handle SNMP queries the plugin gets data from collectd and translates requested values from collectd’s internal format to SNMP format. Supports SNMP: get, getnext and walk requests.
All the plugins above are available on the collectd master, except for the Gnocchi and Aodh plugins as they are Python-based plugins and only C plugins are accepted by the collectd community. The Gnocchi and Aodh plugins live in the OpenStack repositories.
Other plugins existing as a pull request into collectd master:
- Legacy/IPMI: A read plugin that reports platform thermals, voltages, fanspeed, current, flow, power etc. Also, the plugin monitors Intelligent Platform Management Interface (IPMI) System Event Log (SEL) and sends the appropriate notifications based on monitored SEL events.
- PCIe AER: A read plugin that monitors PCIe standard and advanced errors and sends notifications about those errors.
Third party application in Barometer repository:
- Open vSwitch PMD stats: An aplication that retrieves PMD stats from OVS. It is run through exec plugin.
Plugins and application included in the Euphrates release:
Write Plugins: aodh plugin, SNMP agent plugin, gnocchi plugin.
Read Plugins/application: Intel RDT plugin, virt plugin, Open vSwitch stats plugin, Open vSwitch PMD stats application.
Collectd capabilities and usage¶
Note
Plugins included in the OPNFV E release will be built-in for Apex integration and can be configured as shown in the examples below.
The collectd plugins in OPNFV are configured with reasonable defaults, but can be overridden.
Building all Barometer upstreamed plugins from scratch¶
The plugins that have been merged to the collectd master branch can all be built and configured through the barometer repository.
Note
- sudo permissions are required to install collectd.
- These instructions are for Centos 7.
To build all the upstream plugins, clone the barometer repo:
$ git clone https://gerrit.opnfv.org/gerrit/barometer
To install collectd as a service and install all it’s dependencies:
$ cd barometer/systems && ./build_base_machine.sh
This will install collectd as a service and the base install directory will be /opt/collectd.
Sample configuration files can be found in ‘/opt/collectd/etc/collectd.conf.d’
Note
If you don’t want to use one of the Barometer plugins, simply remove the sample config file from ‘/opt/collectd/etc/collectd.conf.d’
Note
If you plan on using the Exec plugin (for OVS_PMD_STATS or for executing scripts on notification generation), the plugin requires a non-root user to execute scripts. By default, collectd_exec user is used in the exec.conf provided in the sample configurations directory under src/collectd in the Barometer repo. These scripts DO NOT create this user. You need to create this user or modify the configuration in the sample configurations directory under src/collectd to use another existing non root user before running build_base_machine.sh.
Note
If you are using any Open vSwitch plugins you need to run:
$ sudo ovs-vsctl set-manager ptcp:6640
After this, you should be able to start collectd as a service
$ sudo systemctl status collectd
If you want to use granfana to display the metrics you collect, please see: grafana guide
For more information on configuring and installing OpenStack plugins for collectd, check out the collectd-ceilometer-plugin GSG.
Below is the per plugin installation and configuration guide, if you only want to install some/particular plugins.
DPDK plugins¶
Repo: https://github.com/collectd/collectd
Branch: master
Dependencies: DPDK (http://dpdk.org/)
Note
DPDK statistics plugin requires DPDK version 16.04 or later.
To build and install DPDK to /usr please see: https://github.com/collectd/collectd/blob/master/docs/BUILD.dpdkstat.md
Building and installing collectd:
$ git clone https://github.com/collectd/collectd.git
$ cd collectd
$ ./build.sh
$ ./configure --enable-syslog --enable-logfile --enable-debug
$ make
$ sudo make install
Note
If DPDK was installed in a non standard location you will need to specify paths to the header files and libraries using LIBDPDK_CPPFLAGS and LIBDPDK_LDFLAGS. You will also need to add the DPDK library symbols to the shared library path using ldconfig. Note that this update to the shared library path is not persistant (i.e. it will not survive a reboot).
Example of specifying custom paths to DPDK headers and libraries:
$ ./configure LIBDPDK_CPPFLAGS="path to DPDK header files" LIBDPDK_LDFLAGS="path to DPDK libraries"
This will install collectd to default folder /opt/collectd. The collectd
configuration file (collectd.conf) can be found at /opt/collectd/etc.
To configure the dpdkstats plugin you need to modify the configuration file to
include:
LoadPlugin dpdkstat
<Plugin dpdkstat>
Coremask "0xf"
ProcessType "secondary"
FilePrefix "rte"
EnabledPortMask 0xffff
PortName "interface1"
PortName "interface2"
</Plugin>
To configure the dpdkevents plugin you need to modify the configuration file to include:
<LoadPlugin dpdkevents>
Interval 1
</LoadPlugin>
<Plugin "dpdkevents">
<EAL>
Coremask "0x1"
MemoryChannels "4"
FilePrefix "rte"
</EAL>
<Event "link_status">
SendEventsOnUpdate false
EnabledPortMask 0xffff
SendNotification true
</Event>
<Event "keep_alive">
SendEventsOnUpdate false
LCoreMask "0xf"
KeepAliveShmName "/dpdk_keepalive_shm_name"
SendNotification true
</Event>
</Plugin>
Note
Currently, the DPDK library doesn’t support API to de-initialize the DPDK resources allocated on the initialization. It means, the collectd plugin will not be able to release the allocated DPDK resources (locks/memory/pci bindings etc.) correctly on collectd shutdown or reinitialize the DPDK library if primary DPDK process is restarted. The only way to release those resources is to terminate the process itself. For this reason, the plugin forks off a separate collectd process. This child process becomes a secondary DPDK process which can be run on specific CPU cores configured by user through collectd configuration file (“Coremask” EAL configuration option, the hexadecimal bitmask of the cores to run on).
For more information on the plugin parameters, please see: https://github.com/collectd/collectd/blob/master/src/collectd.conf.pod
Note
dpdkstat plugin initialization time depends on read interval. It requires 5 read cycles to set up internal buffers and states, during that time no statistics are submitted. Also, if plugin is running and the number of DPDK ports is increased, internal buffers are resized. That requires 3 read cycles and no port statistics are submitted during that time.
The Address-Space Layout Randomization (ASLR) security feature in Linux should be disabled, in order for the same hugepage memory mappings to be present in all DPDK multi-process applications.
To disable ASLR:
$ sudo echo 0 > /proc/sys/kernel/randomize_va_space
To fully enable ASLR:
$ sudo echo 2 > /proc/sys/kernel/randomize_va_space
Warning
Disabling Address-Space Layout Randomization (ASLR) may have security implications. It is recommended to be disabled only when absolutely necessary, and only when all implications of this change have been understood.
For more information on multi-process support, please see: http://dpdk.org/doc/guides/prog_guide/multi_proc_support.html
DPDK stats plugin limitations:
- The DPDK primary process application should use the same version of DPDK that collectd DPDK plugin is using;
- L2 statistics are only supported;
- The plugin has been tested on Intel NIC’s only.
DPDK stats known issues:
DPDK port visibility
When network port controlled by Linux is bound to DPDK driver, the port will not be available in the OS. It affects the SNMP write plugin as those ports will not be present in standard IF-MIB. Thus, additional work is required to be done to support DPDK ports and statistics.
Hugepages Plugin¶
Repo: https://github.com/collectd/collectd
Branch: master
Dependencies: None, but assumes hugepages are configured.
To configure some hugepages:
$ sudo mkdir -p /mnt/huge
$ sudo mount -t hugetlbfs nodev /mnt/huge
$ sudo bash -c "echo 14336 > /sys/devices/system/node/node0/hugepages/hugepages-2048kB/nr_hugepages"
Building and installing collectd:
$ git clone https://github.com/collectd/collectd.git
$ cd collectd
$ ./build.sh
$ ./configure --enable-syslog --enable-logfile --enable-hugepages --enable-debug
$ make
$ sudo make install
This will install collectd to default folder /opt/collectd. The collectd
configuration file (collectd.conf) can be found at /opt/collectd/etc.
To configure the hugepages plugin you need to modify the configuration file to
include:
LoadPlugin hugepages
<Plugin hugepages>
ReportPerNodeHP true
ReportRootHP true
ValuesPages true
ValuesBytes false
ValuesPercentage false
</Plugin>
For more information on the plugin parameters, please see: https://github.com/collectd/collectd/blob/master/src/collectd.conf.pod
Intel PMU Plugin¶
Repo: https://github.com/collectd/collectd
Branch: master
Dependencies:
- PMU tools (jevents library) https://github.com/andikleen/pmu-tools
To be suitable for use in collectd plugin shared library libjevents should be compiled as position-independent code. To do this add the following line to pmu-tools/jevents/Makefile:
CFLAGS += -fPIC
Building and installing jevents library:
$ git clone https://github.com/andikleen/pmu-tools.git
$ cd pmu-tools/jevents/
$ make
$ sudo make install
Building and installing collectd:
$ git clone https://github.com/collectd/collectd.git
$ cd collectd
$ ./build.sh
$ ./configure --enable-syslog --enable-logfile --with-libjevents=/usr/local --enable-debug
$ make
$ sudo make install
This will install collectd to default folder /opt/collectd. The collectd
configuration file (collectd.conf) can be found at /opt/collectd/etc.
To configure the PMU plugin you need to modify the configuration file to
include:
<LoadPlugin intel_pmu>
Interval 1
</LoadPlugin>
<Plugin "intel_pmu">
ReportHardwareCacheEvents true
ReportKernelPMUEvents true
ReportSoftwareEvents true
</Plugin>
For more information on the plugin parameters, please see: https://github.com/collectd/collectd/blob/master/src/collectd.conf.pod
Note
The plugin opens file descriptors whose quantity depends on number of monitored CPUs and number of monitored counters. Depending on configuration, it might be required to increase the limit on the number of open file descriptors allowed. This can be done using ‘ulimit -n’ command. If collectd is executed as a service ‘LimitNOFILE=’ directive should be defined in [Service] section of collectd.service file.
Intel RDT Plugin¶
Repo: https://github.com/collectd/collectd
Branch: master
Dependencies:
- PQoS/Intel RDT library https://github.com/01org/intel-cmt-cat.git
- msr kernel module
Building and installing PQoS/Intel RDT library:
$ git clone https://github.com/01org/intel-cmt-cat.git
$ cd intel-cmt-cat
$ make
$ make install PREFIX=/usr
You will need to insert the msr kernel module:
$ modprobe msr
Building and installing collectd:
$ git clone https://github.com/collectd/collectd.git
$ cd collectd
$ ./build.sh
$ ./configure --enable-syslog --enable-logfile --with-libpqos=/usr/ --enable-debug
$ make
$ sudo make install
This will install collectd to default folder /opt/collectd. The collectd
configuration file (collectd.conf) can be found at /opt/collectd/etc.
To configure the RDT plugin you need to modify the configuration file to
include:
<LoadPlugin intel_rdt>
Interval 1
</LoadPlugin>
<Plugin "intel_rdt">
Cores ""
</Plugin>
For more information on the plugin parameters, please see: https://github.com/collectd/collectd/blob/master/src/collectd.conf.pod
IPMI Plugin¶
Repo: https://github.com/maryamtahhan/collectd
Branch: feat_ipmi_events, feat_ipmi_analog
Dependencies: OpenIPMI library (http://openipmi.sourceforge.net/)
The IPMI plugin is already implemented in the latest collectd and sensors like temperature, voltage, fanspeed, current are already supported there. The list of supported IPMI sensors has been extended and sensors like flow, power are supported now. Also, a System Event Log (SEL) notification feature has been introduced.
- The feat_ipmi_events branch includes new SEL feature support in collectd IPMI plugin. If this feature is enabled, the collectd IPMI plugin will dispatch notifications about new events in System Event Log.
- The feat_ipmi_analog branch includes the support of extended IPMI sensors in collectd IPMI plugin.
Install dependencies
On Centos, install OpenIPMI library:
$ sudo yum install OpenIPMI ipmitool
Anyway, it’s recommended to use the latest version of the OpenIPMI library as it includes fixes of known issues which aren’t included in standard OpenIPMI library package. The latest version of the library can be found at https://sourceforge.net/p/openipmi/code/ci/master/tree/. Steps to install the library from sources are described below.
Remove old version of OpenIPMI library:
$ sudo yum remove OpenIPMI ipmitool
Build and install OpenIPMI library:
$ git clone https://git.code.sf.net/p/openipmi/code openipmi-code
$ cd openipmi-code
$ autoreconf --install
$ ./configure --prefix=/usr
$ make
$ sudo make install
Add the directory containing OpenIPMI*.pc files to the PKG_CONFIG_PATH
environment variable:
export PKG_CONFIG_PATH=/usr/lib/pkgconfig
Enable IPMI support in the kernel:
$ sudo modprobe ipmi_devintf
$ sudo modprobe ipmi_si
Note
If HW supports IPMI, the /dev/ipmi0 character device will be
created.
Clone and install the collectd IPMI plugin:
$ git clone https://github.com/maryamtahhan/collectd
$ cd collectd
$ git checkout $BRANCH
$ ./build.sh
$ ./configure --enable-syslog --enable-logfile --enable-debug
$ make
$ sudo make install
Where $BRANCH is feat_ipmi_events or feat_ipmi_analog.
This will install collectd to default folder /opt/collectd. The collectd
configuration file (collectd.conf) can be found at /opt/collectd/etc.
To configure the IPMI plugin you need to modify the file to include:
LoadPlugin ipmi
<Plugin ipmi>
SELEnabled true # only feat_ipmi_events branch supports this
</Plugin>
Note
By default, IPMI plugin will read all available analog sensor values, dispatch the values to collectd and send SEL notifications.
For more information on the IPMI plugin parameters and SEL feature configuration, please see: https://github.com/maryamtahhan/collectd/blob/feat_ipmi_events/src/collectd.conf.pod
Extended analog sensors support doesn’t require additional configuration. The usual collectd IPMI documentation can be used:
- https://collectd.org/wiki/index.php/Plugin:IPMI
- https://collectd.org/documentation/manpages/collectd.conf.5.shtml#plugin_ipmi
IPMI documentation:
Mcelog Plugin¶
Repo: https://github.com/collectd/collectd
Branch: master
Dependencies: mcelog
Start by installing mcelog.
Note
The kernel has to have CONFIG_X86_MCE enabled. For 32bit kernels you need atleast a 2.6,30 kernel.
On Centos:
$ sudo yum install mcelog
Or build from source
$ git clone https://git.kernel.org/pub/scm/utils/cpu/mce/mcelog.git
$ cd mcelog
$ make
... become root ...
$ make install
$ cp mcelog.service /etc/systemd/system/
$ systemctl enable mcelog.service
$ systemctl start mcelog.service
Verify you got a /dev/mcelog. You can verify the daemon is running completely by running:
$ mcelog --client
This should query the information in the running daemon. If it prints nothing that is fine (no errors logged yet). More info @ http://www.mcelog.org/installation.html
Modify the mcelog configuration file “/etc/mcelog/mcelog.conf” to include or enable:
socket-path = /var/run/mcelog-client
[dimm]
dimm-tracking-enabled = yes
dmi-prepopulate = yes
uc-error-threshold = 1 / 24h
ce-error-threshold = 10 / 24h
[socket]
socket-tracking-enabled = yes
mem-uc-error-threshold = 100 / 24h
mem-ce-error-threshold = 100 / 24h
mem-ce-error-log = yes
[page]
memory-ce-threshold = 10 / 24h
memory-ce-log = yes
memory-ce-action = soft
[trigger]
children-max = 2
directory = /etc/mcelog
Clone and install the collectd mcelog plugin:
$ git clone https://github.com/maryamtahhan/collectd
$ cd collectd
$ ./build.sh
$ ./configure --enable-syslog --enable-logfile --enable-debug
$ make
$ sudo make install
This will install collectd to default folder /opt/collectd. The collectd
configuration file (collectd.conf) can be found at /opt/collectd/etc.
To configure the mcelog plugin you need to modify the configuration file to
include:
<LoadPlugin mcelog>
Interval 1
</LoadPlugin>
<Plugin mcelog>
McelogClientSocket "/var/run/mcelog-client"
</Plugin>
For more information on the plugin parameters, please see: https://github.com/maryamtahhan/collectd/blob/feat_ras/src/collectd.conf.pod
Simulating a Machine Check Exception can be done in one of 3 ways:
- Running $make test in the mcelog cloned directory - mcelog test suite
- using mce-inject
- using mce-test
mcelog test suite:
It is always a good idea to test an error handling mechanism before it is really needed. mcelog includes a test suite. The test suite relies on mce-inject which needs to be installed and in $PATH.
You also need the mce-inject kernel module configured (with CONFIG_X86_MCE_INJECT=y), compiled, installed and loaded:
$ modprobe mce-inject
Then you can run the mcelog test suite with
$ make test
This will inject different classes of errors and check that the mcelog triggers runs. There will be some kernel messages about page offlining attempts. The test will also lose a few pages of memory in your system (not significant). .. note:
This test will kill any running mcelog, which needs to be restarted
manually afterwards.
mce-inject:
A utility to inject corrected, uncorrected and fatal machine check exceptions
$ git clone https://git.kernel.org/pub/scm/utils/cpu/mce/mce-inject.git
$ cd mce-inject
$ make
$ modprobe mce-inject
Modify the test/corrected script to include the following:
CPU 0 BANK 0
STATUS 0xcc00008000010090
ADDR 0x0010FFFFFFF
Inject the error: .. code:: bash
$ ./mce-inject < test/corrected
Note
The uncorrected and fatal scripts under test will cause a platform reset. Only the fatal script generates the memory errors**. In order to quickly emulate uncorrected memory errors and avoid host reboot following test errors from mce-test suite can be injected:
$ mce-inject mce-test/cases/coverage/soft-inj/recoverable_ucr/data/srao_mem_scrub
mce-test:
In addition a more in-depth test of the Linux kernel machine check facilities can be done with the mce-test test suite. mce-test supports testing uncorrected error handling, real error injection, handling of different soft offlining cases, and other tests.
Corrected memory error injection:
To inject corrected memory errors:
- Remove sb_edac and edac_core kernel modules: rmmod sb_edac rmmod edac_core
- Insert einj module: modprobe einj param_extension=1
- Inject an error by specifying details (last command should be repeated at least two times):
$ APEI_IF=/sys/kernel/debug/apei/einj
$ echo 0x8 > $APEI_IF/error_type
$ echo 0x01f5591000 > $APEI_IF/param1
$ echo 0xfffffffffffff000 > $APEI_IF/param2
$ echo 1 > $APEI_IF/notrigger
$ echo 1 > $APEI_IF/error_inject
- Check the MCE statistic: mcelog –client. Check the mcelog log for injected error details: less /var/log/mcelog.
Open vSwitch Plugins¶
OvS Plugins Repo: https://github.com/collectd/collectd
OvS Plugins Branch: master
OvS Events MIBs: The SNMP OVS interface link status is provided by standard IF-MIB (http://www.net-snmp.org/docs/mibs/IF-MIB.txt)
Dependencies: Open vSwitch, Yet Another JSON Library (https://github.com/lloyd/yajl)
On Centos, install the dependencies and Open vSwitch:
$ sudo yum install yajl-devel
Steps to install Open vSwtich can be found at http://docs.openvswitch.org/en/latest/intro/install/fedora/
Start the Open vSwitch service:
$ sudo service openvswitch-switch start
Configure the ovsdb-server manager:
$ sudo ovs-vsctl set-manager ptcp:6640
Clone and install the collectd ovs plugin:
$ git clone $REPO
$ cd collectd
$ git checkout master
$ ./build.sh
$ ./configure --enable-syslog --enable-logfile --enable-debug
$ make
$ sudo make install
This will install collectd to default folder /opt/collectd. The collectd
configuration file (collectd.conf) can be found at /opt/collectd/etc.
To configure the OVS events plugin you need to modify the configuration file to include:
<LoadPlugin ovs_events>
Interval 1
</LoadPlugin>
<Plugin ovs_events>
Port "6640"
Address "127.0.0.1"
Socket "/var/run/openvswitch/db.sock"
Interfaces "br0" "veth0"
SendNotification true
</Plugin>
To configure the OVS stats plugin you need to modify the configuration file to include:
<LoadPlugin ovs_stats>
Interval 1
</LoadPlugin>
<Plugin ovs_stats>
Port "6640"
Address "127.0.0.1"
Socket "/var/run/openvswitch/db.sock"
Bridges "br0"
</Plugin>
For more information on the plugin parameters, please see: https://github.com/collectd/collectd/blob/master/src/collectd.conf.pod
OVS PMD stats¶
Repo: https://gerrit.opnfv.org/gerrit/barometer
Prequistes: 1. Open vSwitch dependencies are installed. 2. Open vSwitch service is running. 3. Ovsdb-server manager is configured. You can refer Open vSwitch Plugins section above for each one of them.
OVS PMD stats application is run through the exec plugin.
To configure the OVS PMD stats application you need to modify the exec plugin configuration to include:
<LoadPlugin exec>
Interval 1
</LoadPlugin
<Plugin exec>
Exec "user:group" "<path to ovs_pmd_stat.sh>"
</Plugin>
Note
Exec plugin configuration has to be changed to use appropriate user before starting collectd service.
ovs_pmd_stat.sh calls the script for OVS PMD stats application with its argument:
sudo python /usr/local/src/ovs_pmd_stats.py" "--socket-pid-file"
"/var/run/openvswitch/ovs-vswitchd.pid"
SNMP Agent Plugin¶
Repo: https://github.com/maryamtahhan/collectd/
Branch: master
Dependencies: NET-SNMP library
Start by installing net-snmp and dependencies.
On Centos 7:
$ sudo yum install net-snmp net-snmp-libs net-snmp-utils net-snmp-devel
$ sudo systemctl start snmpd.service
go to the snmp configuration steps.
From source:
Clone and build net-snmp:
$ git clone https://github.com/haad/net-snmp.git
$ cd net-snmp
$ ./configure --with-persistent-directory="/var/net-snmp" --with-systemd --enable-shared --prefix=/usr
$ make
Become root
$ make install
Copy default configuration to persistent folder:
$ cp EXAMPLE.conf /usr/share/snmp/snmpd.conf
Set library path and default MIB configuration:
$ cd ~/
$ echo export LD_LIBRARY_PATH=/usr/lib >> .bashrc
$ net-snmp-config --default-mibdirs
$ net-snmp-config --snmpconfpath
Configure snmpd as a service:
$ cd net-snmp
$ cp ./dist/snmpd.service /etc/systemd/system/
$ systemctl enable snmpd.service
$ systemctl start snmpd.service
Add the following line to snmpd.conf configuration file
/etc/snmp/snmpd.conf to make all OID tree visible for SNMP clients:
view systemview included .1
To verify that SNMP is working you can get IF-MIB table using SNMP client to view the list of Linux interfaces:
$ snmpwalk -v 2c -c public localhost IF-MIB::interfaces
Get the default MIB location:
$ net-snmp-config --default-mibdirs
/opt/stack/.snmp/mibs:/usr/share/snmp/mibs
Install Intel specific MIBs (if needed) into location received by
net-snmp-config command (e.g. /usr/share/snmp/mibs).
$ git clone https://gerrit.opnfv.org/gerrit/barometer.git
$ sudo cp -f barometer/mibs/*.txt /usr/share/snmp/mibs/
$ sudo systemctl restart snmpd.service
Clone and install the collectd snmp_agent plugin:
$ cd ~
$ git clone https://github.com/maryamtahhan/collectd
$ cd collectd
$ git checkout feat_snmp
$ ./build.sh
$ ./configure --enable-syslog --enable-logfile --enable-debug --enable-snmp --with-libnetsnmp
$ make
$ sudo make install
This will install collectd to default folder /opt/collectd. The collectd
configuration file (collectd.conf) can be found at /opt/collectd/etc.
SNMP Agent plugin is a generic plugin and cannot work without configuration. To configure the snmp_agent plugin you need to modify the configuration file to include OIDs mapped to collectd types. The following example maps scalar memAvailReal OID to value represented as free memory type of memory plugin:
LoadPlugin snmp_agent
<Plugin "snmp_agent">
<Data "memAvailReal">
Plugin "memory"
Type "memory"
TypeInstance "free"
OIDs "1.3.6.1.4.1.2021.4.6.0"
</Data>
</Plugin>
The snmpwalk command can be used to validate the collectd configuration:
$ snmpwalk -v 2c -c public localhost 1.3.6.1.4.1.2021.4.6.0
UCD-SNMP-MIB::memAvailReal.0 = INTEGER: 135237632 kB
Limitations
- Object instance with Counter64 type is not supported in SNMPv1. When GetNext request is received, Counter64 type objects will be skipped. When Get request is received for Counter64 type object, the error will be returned.
- Interfaces that are not visible to Linux like DPDK interfaces cannot be retreived using standard IF-MIB tables.
For more information on the plugin parameters, please see: https://github.com/maryamtahhan/collectd/blob/feat_snmp/src/collectd.conf.pod
For more details on AgentX subagent, please see: http://www.net-snmp.org/tutorial/tutorial-5/toolkit/demon/
virt plugin¶
Repo: https://github.com/maryamtahhan/collectd
Branch: master
Dependencies: libvirt (https://libvirt.org/), libxml2
On Centos, install the dependencies:
$ sudo yum install libxml2-dev libpciaccess-devel yajl-devel device-mapper-devel
Install libvirt:
libvirt version in package manager might be quite old and offer only limited functionality. Hence, building and installing libvirt from sources is recommended. Detailed instructions can bet found at: https://libvirt.org/compiling.html
Certain metrics provided by the plugin have a requirement on a minimal version of the libvirt API. File system information statistics require a Guest Agent (GA) to be installed and configured in a VM. User must make sure that installed GA version supports retrieving file system information. Number of Performance monitoring events metrics depends on running libvirt daemon version.
Note
Please keep in mind that RDT metrics (part of Performance monitoring events) have to be supported by hardware. For more details on hardware support, please see: https://github.com/01org/intel-cmt-cat
Additionally perf metrics cannot be collected if Intel RDT plugin is enabled.
libvirt version can be checked with following commands:
$ virsh --version
$ libvirtd --version
| Statistic | Min. libvirt API version | Requires GA |
|---|---|---|
| Domain reason | 0.9.2 | No |
| Disk errors | 0.9.10 | No |
| Job statistics | 1.2.9 | No |
| File system information | 1.2.11 | Yes |
| Performance monitoring events | 1.3.3 | No |
Start libvirt daemon:
$ systemctl start libvirtd
Create domain (VM) XML configuration file. For more information on domain XML format and examples, please see: https://libvirt.org/formatdomain.html
Note
Installing additional hypervisor dependencies might be required before deploying virtual machine.
Create domain, based on created XML file:
$ virsh define DOMAIN_CFG_FILE.xml
Start domain:
$ virsh start DOMAIN_NAME
Check if domain is running:
$ virsh list
Check list of available Performance monitoring events and their settings:
$ virsh perf DOMAIN_NAME
Enable or disable Performance monitoring events for domain:
$ virsh perf DOMAIN_NAME [--enable | --disable] EVENT_NAME --live
Clone and install the collectd virt plugin:
$ git clone $REPO
$ cd collectd
$ ./build.sh
$ ./configure --enable-syslog --enable-logfile --enable-debug
$ make
$ sudo make install
Where $REPO is equal to information provided above.
This will install collectd to /opt/collectd. The collectd configuration file
collectd.conf can be found at /opt/collectd/etc.
To load the virt plugin user needs to modify the configuration file to include:
LoadPlugin virt
Additionally, user can specify plugin configuration parameters in this file,
such as connection URL, domain name and much more. By default extended virt plugin
statistics are disabled. They can be enabled with ExtraStats option.
<Plugin virt>
RefreshInterval 60
ExtraStats "cpu_util disk disk_err domain_state fs_info job_stats_background pcpu perf vcpupin"
</Plugin>
For more information on the plugin parameters, please see: https://github.com/maryamtahhan/collectd/blob/feat_libvirt_upstream/src/collectd.conf.pod
Installing collectd as a service¶
NOTE: In an OPNFV installation, collectd is installed and configured as a service.
Collectd service scripts are available in the collectd/contrib directory. To install collectd as a service:
$ sudo cp contrib/systemd.collectd.service /etc/systemd/system/
$ cd /etc/systemd/system/
$ sudo mv systemd.collectd.service collectd.service
$ sudo chmod +x collectd.service
Modify collectd.service
[Service]
ExecStart=/opt/collectd/sbin/collectd
EnvironmentFile=-/opt/collectd/etc/
EnvironmentFile=-/opt/collectd/etc/
CapabilityBoundingSet=CAP_SETUID CAP_SETGID
Reload
$ sudo systemctl daemon-reload
$ sudo systemctl start collectd.service
$ sudo systemctl status collectd.service should show success
Additional useful plugins¶
- Exec Plugin : Can be used to show you when notifications are being
generated by calling a bash script that dumps notifications to file. (handy for debug). Modify /opt/collectd/etc/collectd.conf:
LoadPlugin exec
<Plugin exec>
# Exec "user:group" "/path/to/exec"
NotificationExec "user" "<path to barometer>/barometer/src/collectd/collectd_sample_configs/write_notification.sh"
</Plugin>
write_notification.sh (just writes the notification passed from exec through STDIN to a file (/tmp/notifications)):
#!/bin/bash
rm -f /tmp/notifications
while read x y
do
echo $x$y >> /tmp/notifications
done
output to /tmp/notifications should look like:
Severity:WARNING
Time:1479991318.806
Host:localhost
Plugin:ovs_events
PluginInstance:br-ex
Type:gauge
TypeInstance:link_status
uuid:f2aafeec-fa98-4e76-aec5-18ae9fc74589
linkstate of "br-ex" interface has been changed to "DOWN"
- logfile plugin: Can be used to log collectd activity. Modify /opt/collectd/etc/collectd.conf to include:
LoadPlugin logfile
<Plugin logfile>
LogLevel info
File "/var/log/collectd.log"
Timestamp true
PrintSeverity false
</Plugin>
Monitoring Interfaces and Openstack Support¶
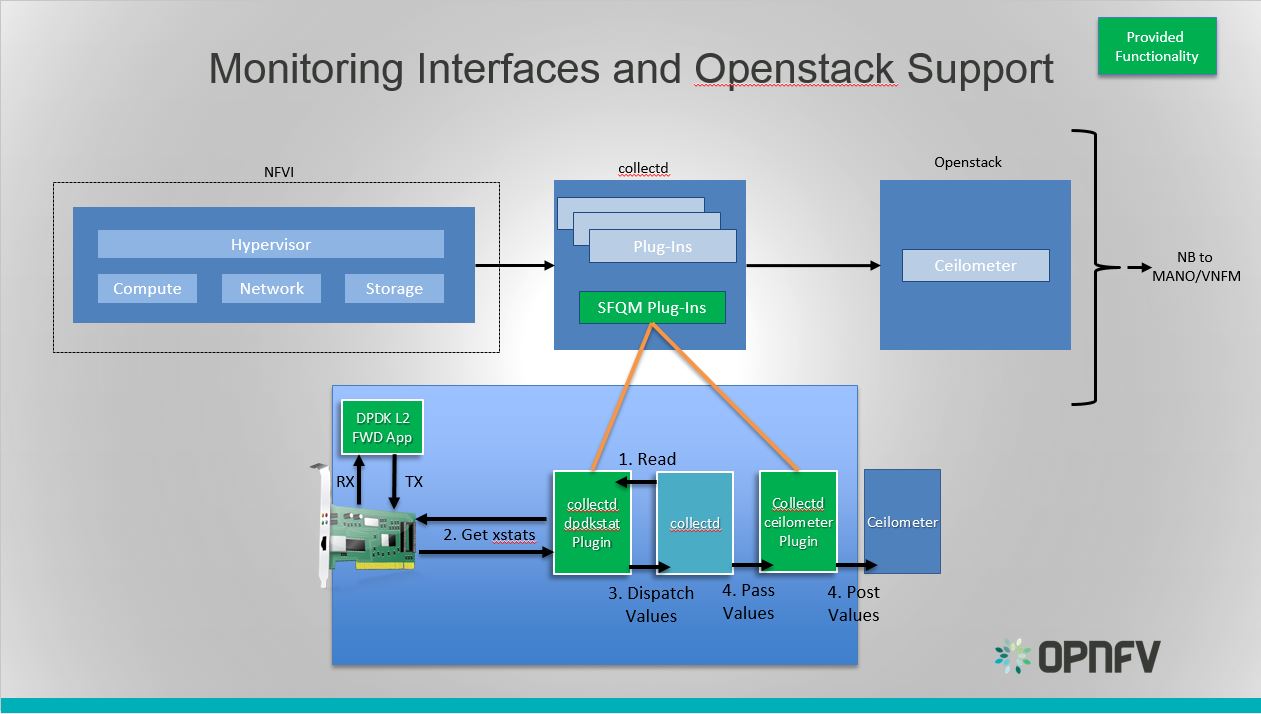
Monitoring Interfaces and Openstack Support
The figure above shows the DPDK L2 forwarding application running on a compute node, sending and receiving traffic. Collectd is also running on this compute node retrieving the stats periodically from DPDK through the dpdkstat plugin and publishing the retrieved stats to OpenStack through the collectd-ceilometer-plugin.
To see this demo in action please checkout: Barometer OPNFV Summit demo
For more information on configuring and installing OpenStack plugins for collectd, check out the collectd-ceilometer-plugin GSG.
References¶
| [1] | https://collectd.org/wiki/index.php/Naming_schema |
| [2] | https://github.com/collectd/collectd/blob/master/src/daemon/plugin.h |
| [3] | https://collectd.org/wiki/index.php/Value_list_t |
| [4] | https://collectd.org/wiki/index.php/Data_set |
| [5] | https://collectd.org/documentation/manpages/types.db.5.shtml |
| [6] | https://collectd.org/wiki/index.php/Data_source |
| [7] | https://collectd.org/wiki/index.php/Meta_Data_Interface |
VES Application User Guide¶
The Barometer repository contains a python based application for VES.
The application currently supports pushing platform relevant metrics through the additional measurements field for VES.
Collectd has a write_kafka plugin that will send collectd metrics and values to a Kafka Broker. The VES application uses Kafka Consumer to receive metrics from the Kafka Broker.
Installation Instructions:¶
Clone this repo:
git clone https://gerrit.opnfv.org/gerrit/barometer
Install collectd
$ sudo apt-get install collectd
CentOS 7.x use:
$ sudo yum install collectd
Note
You may need to add epel repository if the above does not work.
$ sudo yun install epel-release
Modify the collectd configuration script: /etc/collectd/collectd.conf
<Plugin write_kafka> Property "metadata.broker.list" "localhost:9092" <Topic "collectd"> Format JSON </Topic> </Plugin>Note
The above configuration is for a single host setup. Simply change localhost to remote server IP addess or hostname.
Install Kafka Broker¶
Dependencies: install JAVA & Zookeeper.
JAVA:
$ sudo apt install default-jre
CentOS 7.x use:
$ sudo yum install java-1.6.0-openjdk
Zookeeper:
$ sudo apt install zookeeperd
CentOS 7.x use:
$ sudo yum install zookeeper
Note
You may need to add the the repository that contains zookeeper
$ sudo yum install https://archive.cloudera.com/cdh5/one-click-install/redhat/7/x86_64/cloudera-cdh-5-0.x86_64.rpm
CentOS 7.x start zookeeper:
$ sudo zookeeper-server start
To test if Zookeeper is running as a daemon.
$ sudo telnet localhost 2181
Type ‘ruok’ & hit enter. Expected response is ‘imok’. Zookeeper is running fine.
Note
VES doesn’t work with version 0.9.4 of kafka-python. The recommended/tested version is 1.3.3.
$ sudo pip install kafka-python
Download Kafka:
$ sudo wget "http://www-eu.apache.org/dist/kafka/0.11.0.0/kafka_2.11-0.11.0.0.tgz"
Extract the archive:
$ sudo tar -xvzf kafka_2.11-0.11.0.0.tgz
Configure Kafka Server:
$ sudo vi kafka_2.11-0.11.0.0/config/server.properties
By default Kafka does not allow you to delete topics. Please uncomment:
delete.topic.enable=true
Start the Kafka Server.
Run ‘kafka-server-start.sh’ with nohup as a background process:
$ sudo nohup kafka_2.11-0.11.0.0/bin/kafka-server-start.sh \ kafka_2.11-0.11.0.0/config/server.properties > kafka_2.11-0.11.0.0/kafka.log 2>&1 &
Test Kafka Broker Installation
To test if the installation worked correctly there are two scripts, producer and consumer scripts. These will allow you to see messages pushed to broker and receive from broker.
Producer (Publish “Hello World”):
$ echo "Hello, World" | kafka_2.11-0.11.0.0/bin/kafka-console-producer.sh \ --broker-list localhost:9092 --topic TopicTest > /dev/null
Consumer (Receive “Hello World”):
$ kafka_2.11-0.11.0.0/bin/kafka-console-consumer.sh --zookeeper \ localhost:2181 --topic TopicTest --from-beginning
VES application configuration description:¶
Within the VES directory there is a configuration file called ‘ves_app.conf’.
Note
Details of the Vendor Event Listener REST service
REST resources are defined with respect to a ServerRoot:
ServerRoot = https://{Domain}:{Port}/{optionalRoutingPath}
REST resources are of the form:
{ServerRoot}/eventListener/v{apiVersion}`
{ServerRoot}/eventListener/v{apiVersion}/{topicName}`
{ServerRoot}/eventListener/v{apiVersion}/eventBatch`
- Domain “host”
- VES domain name. It can be IP address or hostname of VES collector (default: 127.0.0.1)
- Port port
- VES port (default: 30000)
- Path “path”
- Used as the “optionalRoutingPath” element in the REST path (default: empty)
- Topic “path”
- Used as the “topicName” element in the REST path (default: empty)
- UseHttps true|false
- Allow application to use HTTPS instead of HTTP (default: false)
- Username “username”
- VES collector user name (default: empty)
- Password “passwd”
- VES collector password (default: empty)
- FunctionalRole “role”
- Used as the ‘functionalRole’ field of ‘commonEventHeader’ event (default: Collectd VES Agent)
- SendEventInterval interval
- This configuration option controls how often (sec) collectd data is sent to Vendor Event Listener (default: 20)
- ApiVersion version
- Used as the “apiVersion” element in the REST path (default: 5.1)
- KafkaPort port
- Kafka Port (Default
9092) - KafkaBroker host
- Kafka Broker domain name. It can be an IP address or hostname of local or remote server (default: localhost)
Other collectd.conf configurations¶
Please ensure that FQDNLookup is set to false
FQDNLookup false
Please ensure that the virt plugin is enabled and configured as follows.
LoadPlugin virt
<Plugin virt>
Connection "qemu:///system"
RefreshInterval 60
HostnameFormat uuid
PluginInstanceFormat name
ExtraStats "cpu_util perf"
</Plugin>
Note
For more detailed information on the virt plugin configuration, requirements etc., please see the userguide of the collectd virt plugin.
Please ensure that the cpu plugin is enabled and configured as follows
LoadPlugin cpu
<Plugin cpu>
ReportByCpu false
ValuesPercentage true
</Plugin>
Note
The ReportByCpu option should be set to true (default)
if VES application is running on guest machine (‘GuestRunning’ = true).
Please ensure that the aggregation plugin is enabled and configured as follows (required if ‘GuestRunning’ = true)
LoadPlugin aggregation
<Plugin aggregation>
<Aggregation>
Plugin "cpu"
Type "percent"
GroupBy "Host"
GroupBy "TypeInstance"
SetPlugin "cpu-aggregation"
CalculateAverage true
</Aggregation>
</Plugin>
If application is running on a guest side, it is important to enable uuid plugin too. In this case the hostname in event message will be represented as UUID instead of system host name.
LoadPlugin uuid
If a custom UUID needs to be provided, the following configuration is required in collectd.conf file:
<Plugin uuid>
UUIDFile "/etc/uuid"
</Plugin>
Where “/etc/uuid” is a file containing custom UUID.
Please also ensure that the following plugins are enabled:
LoadPlugin disk
LoadPlugin interface
LoadPlugin memory
VES application with collectd notifications example¶
A good example of collectD notification is monitoring of the total CPU usage on a VM using the ‘threshold’ plugin. The following configuration will setup VES plugin to send ‘Fault’ event every time a total VM CPU value is out of range (e.g.: WARNING: VM CPU TOTAL > 50%, CRITICAL: VM CPU TOTAL > 96%) and send ‘Fault’ NORMAL event if the CPU value is back to normal. In the example below, there is one VM with two CPUs configured which is running on the host with a total of 48 cores. Thus, the threshold value 2.08 (100/48) means that one CPU of the VM is fully loaded (e.g.: 50% of total CPU usage of the VM) and 4.0 means 96% of total CPU usage of the VM. Those values can also be obtained by virt-top command line tool.
LoadPlugin threshold
<Plugin "threshold">
<Plugin "virt">
<Type "percent">
WarningMax 2.08
FailureMax 4.0
Instance "virt_cpu_total"
</Type>
</Plugin>
</Plugin>
More detailed information on how to configure collectD thresholds can be found at https://collectd.org/documentation/manpages/collectd-threshold.5.shtml
OPNFV Barometer Release Notes¶
Barometer Release Notes¶
This document provides the release notes for Euphrates release of Barometer.
Important notes¶
None to date.
Summary¶
The Barometer@OPNFV project adds a platform telemetry agent to compute nodes that is capable of retrieving platform statistics and events, and relay them to Openstack Gnocchi and Aodh. The telemetry agent currently supported by barometer is collectd. Some additional collectd plugins and application were developed to add the following functionality:
Write/publishing Plugins:
- aodh plugin: A notification plugin that pushes events to Aodh, and creates/updates alarms appropriately.
- SNMP agent plugin: A write plugin that will act as an AgentX subagent that receives and handles queries from SNMP master agent and returns the data collected by read plugins. The SNMP Agent plugin handles requests only for OIDs specified in configuration file. To handle SNMP queries the plugin gets data from collectd and translates requested values from collectd’s internal format to SNMP format. Supports SNMP: get, getnext and walk requests.
- gnocchi plugin: A write plugin that pushes the retrieved stats to Gnocchi. It’s capable of pushing any stats read through collectd to Gnocchi, not just the DPDK stats.
Read Plugins:
- Intel RDT plugin: A read plugin that provides the last level cache utilization and memory bandwidth utilization.
- virt plugin: A read plugin that uses virtualization API libvirt to gather statistics and events about virtualized guests on a system directly from the hypervisor, without a need to install collectd instance on the guest.
- Open vSwitch stats plugin: A read plugin that retrieves interface stats from OVS.
In addition to the previous plugins from the Danube Release described below.
Release Data¶
| Project | Euphrates/barometer/barometer@opnfv |
| Repo/commit-ID | barometer/ |
| Release designation | Euphrates 5.0 |
| Release date | October 20th, 2017 |
| Purpose of the delivery | Official OPNFV release |
Version change¶
Module version changes¶
- There have been no version changes.
Document version changes¶
Reason for version¶
Feature additions¶
JIRA BACK-LOG:
| JIRA REFERENCE | SLOGAN |
| BAROMETER-51 | RDT Cache Feature |
| BAROMETER-53 | RAS Metrics and Events/ MCELOG Memory Errors |
| BAROMETER-55 | Libvirt Metrics and Events |
| BAROMETER-56 | Openvswitch Mrtics and Events |
| BAROMETER-59 | AODH plugin |
| BAROMETER-60 | Gnocchi Plugin |
| BAROMETER-58 | SNMP Agent |
Bugs¶
JIRA TICKETS:
| JIRA REFERENCE | SLOGAN |
| BAROMETER-80 | SNMP Agent testing with Intel RDT, MCELOG, Hugepages, and OVS Stats not functional in the Apex image of OPNFV Release E |
Deliverables¶
Software deliverables¶
Features to Date¶
Release B¶
The features implemented for OPNFV release B (as part of SFQM) in DPDK include:
- Callback API to enable TX/RX timestamping to measure latency through DPDK.
- Extended NIC statistics API for 1GB, 10GB and 40GB NICs to expose detailed statistics for DPDK interfaces in addition to the overall aggregate statistics.
- DPDK Keep Alive.
Release C¶
The features implemented for OPNFV release C (as part of SFQM) include:
- DPDK extended NIC stats API improvement; migrate from key value pairs to using id value pairs.
- DPDK Keep Alive improvement, so that core status is exposed through a posix shared memory object.
- collectd dpdkstat plugin that can retrieve DPDK interface statistics.
- collectd ceilometer plugin that can publish any statistics collected by collectd to ceilometer.
- Fuel plugin support for the collectd ceilometer plugin for OPNFV.
Release D¶
The features implemented for OPNFV release D include:
- collectd hugepages plugin that can retrieves the number of available and free hugepages on a platform as well as what is available in terms of hugepages per socket.
- collectd Open vSwitch Events plugin that can retrieves events from OVS.
- collectd mcelog plugin that can use mcelog client protocol to check for memory Machine Check Exceptions and sends the stats for reported exceptions.
- collectd ceilometer plugin that can publish any statistics collected by collectd to ceilometer.
Documentation deliverables¶
- Configuration guide
- User guide
- Release notes
- Scenario documentation.
Known Limitations, Issues and Workarounds¶
System Limitations¶
For Intel RDT plugin, compute node needs to support Intel RDT.
Workarounds¶
- None to date.
Test Result¶
Barometer@OPNFV Euphrates has undergone QA test runs with the following results:
| TEST-SUITE | Results: |
| barometercollectd | |
References¶
OPNFV Barometer Requirements¶
Problem Statement¶
Providing carrier grade Service Assurance is critical in the network transformation to a software defined and virtualized network (NFV). Medium-/large-scale cloud environments account for between hundreds and hundreds of thousands of infrastructure systems. It is vital to monitor systems for malfunctions that could lead to users application service disruption and promptly react to these fault events to facilitate improving overall system performance. As the size of infrastructure and virtual resources grow, so does the effort of monitoring back-ends. SFQM aims to expose as much useful information as possible off the platform so that faults and errors in the NFVI can be detected promptly and reported to the appropriate fault management entity.
The OPNFV platform (NFVI) requires functionality to:
- Create a low latency, high performance packet processing path (fast path) through the NFVI that VNFs can take advantage of;
- Measure Telco Traffic and Performance KPIs through that fast path;
- Detect and report violations that can be consumed by VNFs and higher level EMS/OSS systems
Examples of local measurable QoS factors for Traffic Monitoring which impact both Quality of Experience and five 9’s availability would be (using Metro Ethernet Forum Guidelines as reference):
- Packet loss
- Packet Delay Variation
- Uni-directional frame delay
Other KPIs such as Call drops, Call Setup Success Rate, Call Setup time etc. are measured by the VNF.
In addition to Traffic Monitoring, the NFVI must also support Performance Monitoring of the physical interfaces themselves (e.g. NICs), i.e. an ability to monitor and trace errors on the physical interfaces and report them.
All these traffic statistics for Traffic and Performance Monitoring must be measured in-service and must be capable of being reported by standard Telco mechanisms (e.g. SNMP traps), for potential enforcement actions.
Barometer updated scope¶
The scope of the project is to provide interfaces to support monitoring of the NFVI. The project will develop plugins for telemetry frameworks to enable the collection of platform stats and events and relay gathered information to fault management applications or the VIM. The scope is limited to collecting/gathering the events and stats and relaying them to a relevant endpoint. The project will not enforce or take any actions based on the gathered information.
Scope of SFQM¶
NOTE: The SFQM project has been replaced by Barometer. The output of the project will provide interfaces and functions to support monitoring of Packet Latency and Network Interfaces while the VNF is in service.
The DPDK interface/API will be updated to support:
- Exposure of NIC MAC/PHY Level Counters
- Interface for Time stamp on RX
- Interface for Time stamp on TX
- Exposure of DPDK events
collectd will be updated to support the exposure of DPDK metrics and events.
Specific testing and integration will be carried out to cover:
- Unit/Integration Test plans: A sample application provided to demonstrate packet latency monitoring and interface monitoring
The following list of features and functionality will be developed:
- DPDK APIs and functions for latency and interface monitoring
- A sample application to demonstrate usage
- collectd plugins
The scope of the project involves developing the relavant DPDK APIs, OVS APIs, sample applications, as well as the utilities in collectd to export all the relavent information to a telemetry and events consumer.
VNF specific processing, Traffic Monitoring, Performance Monitoring and Management Agent are out of scope.
The Proposed Interface counters include:
- Packet RX
- Packet TX
- Packet loss
- Interface errors + other stats
The Proposed Packet Latency Monitor include:
- Cycle accurate stamping on ingress
- Supports latency measurements on egress
Support for failover of DPDK enabled cores is also out of scope of the current proposal. However, this is an important requirement and must-have functionality for any DPDK enabled framework in the NFVI. To that end, a second phase of this project will be to implement DPDK Keep Alive functionality that would address this and would report to a VNF-level Failover and High Availability mechanism that would then determine what actions, including failover, may be triggered.
Consumption Models¶
In reality many VNFs will have an existing performance or traffic monitoring utility used to monitor VNF behavior and report statistics, counters, etc.
The consumption of performance and traffic related information/events provided by this project should be a logical extension of any existing VNF/NFVI monitoring framework. It should not require a new framework to be developed. We do not see the Barometer gathered metrics and evetns as major additional effort for monitoring frameworks to consume; this project would be sympathetic to existing monitoring frameworks. The intention is that this project represents an interface for NFVI monitoring to be used by higher level fault management entities (see below).
Allowing the Barometer metrics and events to be handled within existing telemetry frameoworks makes it simpler for overall interfacing with higher level management components in the VIM, MANO and OSS/BSS. The Barometer proposal would be complementary to the Doctor project, which addresses NFVI Fault Management support in the VIM, and the VES project, which addresses the integration of VNF telemetry-related data into automated VNF management systems. To that end, the project committers and contributors for the Barometer project wish to collaborate with the Doctor and VES projects to facilitate this.
collectd¶
collectd is a daemon which collects system performance statistics periodically and provides a variety of mechanisms to publish the collected metrics. It supports more than 90 different input and output plugins. Input plugins retrieve metrics and publish them to the collectd deamon, while output plugins publish the data they receive to an end point. collectd also has infrastructure to support thresholding and notification.
collectd statistics and Notifications¶
Within collectd notifications and performance data are dispatched in the same way. There are producer plugins (plugins that create notifications/metrics), and consumer plugins (plugins that receive notifications/metrics and do something with them).
Statistics in collectd consist of a value list. A value list includes:
- Values, can be one of:
- Derive: used for values where a change in the value since it’s last been read is of interest. Can be used to calculate and store a rate.
- Counter: similar to derive values, but take the possibility of a counter wrap around into consideration.
- Gauge: used for values that are stored as is.
- Absolute: used for counters that are reset after reading.
- Value length: the number of values in the data set.
- Time: timestamp at which the value was collected.
- Interval: interval at which to expect a new value.
- Host: used to identify the host.
- Plugin: used to identify the plugin.
- Plugin instance (optional): used to group a set of values together. For e.g. values belonging to a DPDK interface.
- Type: unit used to measure a value. In other words used to refer to a data set.
- Type instance (optional): used to distinguish between values that have an identical type.
- meta data: an opaque data structure that enables the passing of additional information about a value list. “Meta data in the global cache can be used to store arbitrary information about an identifier” [7].
Host, plugin, plugin instance, type and type instance uniquely identify a collectd value.
Values lists are often accompanied by data sets that describe the values in more detail. Data sets consist of:
- A type: a name which uniquely identifies a data set.
- One or more data sources (entries in a data set) which include:
- The name of the data source. If there is only a single data source this is set to “value”.
- The type of the data source, one of: counter, gauge, absolute or derive.
- A min and a max value.
Types in collectd are defined in types.db. Examples of types in types.db:
bitrate value:GAUGE:0:4294967295
counter value:COUNTER:U:U
if_octets rx:COUNTER:0:4294967295, tx:COUNTER:0:4294967295
In the example above if_octets has two data sources: tx and rx.
Notifications in collectd are generic messages containing:
- An associated severity, which can be one of OKAY, WARNING, and FAILURE.
- A time.
- A Message
- A host.
- A plugin.
- A plugin instance (optional).
- A type.
- A types instance (optional).
- Meta-data.
DPDK Enhancements¶
This section will discuss the Barometer features that were integrated with DPDK.
Measuring Telco Traffic and Performance KPIs¶
This section will discuss the Barometer features that enable Measuring Telco Traffic and Performance KPIs.
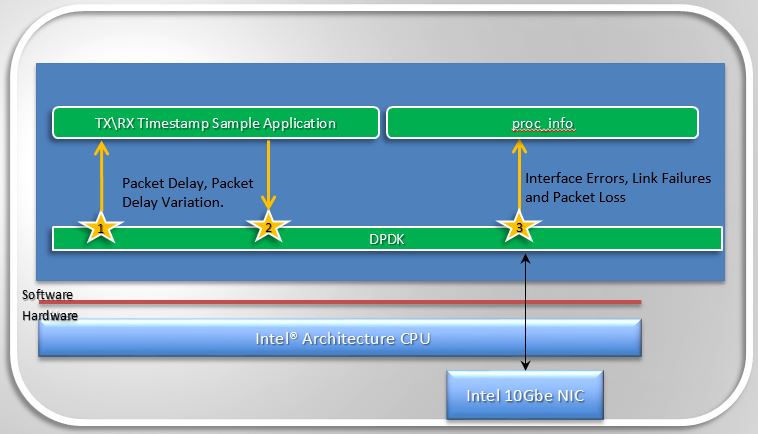
Measuring Telco Traffic and Performance KPIs
- The very first thing Barometer enabled was a call-back API in DPDK and an associated application that used the API to demonstrate how to timestamp packets and measure packet latency in DPDK (the sample app is called rxtx_callbacks). This was upstreamed to DPDK 2.0 and is represented by the interfaces 1 and 2 in Figure 1.2.
- The second thing Barometer implemented in DPDK is the extended NIC statistics API,
which exposes NIC stats including error stats to the DPDK user by reading the
registers on the NIC. This is represented by interface 3 in Figure 1.2.
- For DPDK 2.1 this API was only implemented for the ixgbe (10Gb) NIC driver, in association with a sample application that runs as a DPDK secondary process and retrieves the extended NIC stats.
- For DPDK 2.2 the API was implemented for igb, i40e and all the Virtual Functions (VFs) for all drivers.
- For DPDK 16.07 the API migrated from using string value pairs to using id value pairs, improving the overall performance of the API.
Monitoring DPDK interfaces¶
With the features Barometer enabled in DPDK to enable measuring Telco traffic and performance KPIs, we can now retrieve NIC statistics including error stats and relay them to a DPDK user. The next step is to enable monitoring of the DPDK interfaces based on the stats that we are retrieving from the NICs, by relaying the information to a higher level Fault Management entity. To enable this Barometer has been enabling a number of plugins for collectd.
DPDK Keep Alive description¶
SFQM aims to enable fault detection within DPDK, the very first feature to meet this goal is the DPDK Keep Alive Sample app that is part of DPDK 2.2.
DPDK Keep Alive or KA is a sample application that acts as a heartbeat/watchdog for DPDK packet processing cores, to detect application thread failure. The application supports the detection of ‘failed’ DPDK cores and notification to a HA/SA middleware. The purpose is to detect Packet Processing Core fails (e.g. infinite loop) and ensure the failure of the core does not result in a fault that is not detectable by a management entity.
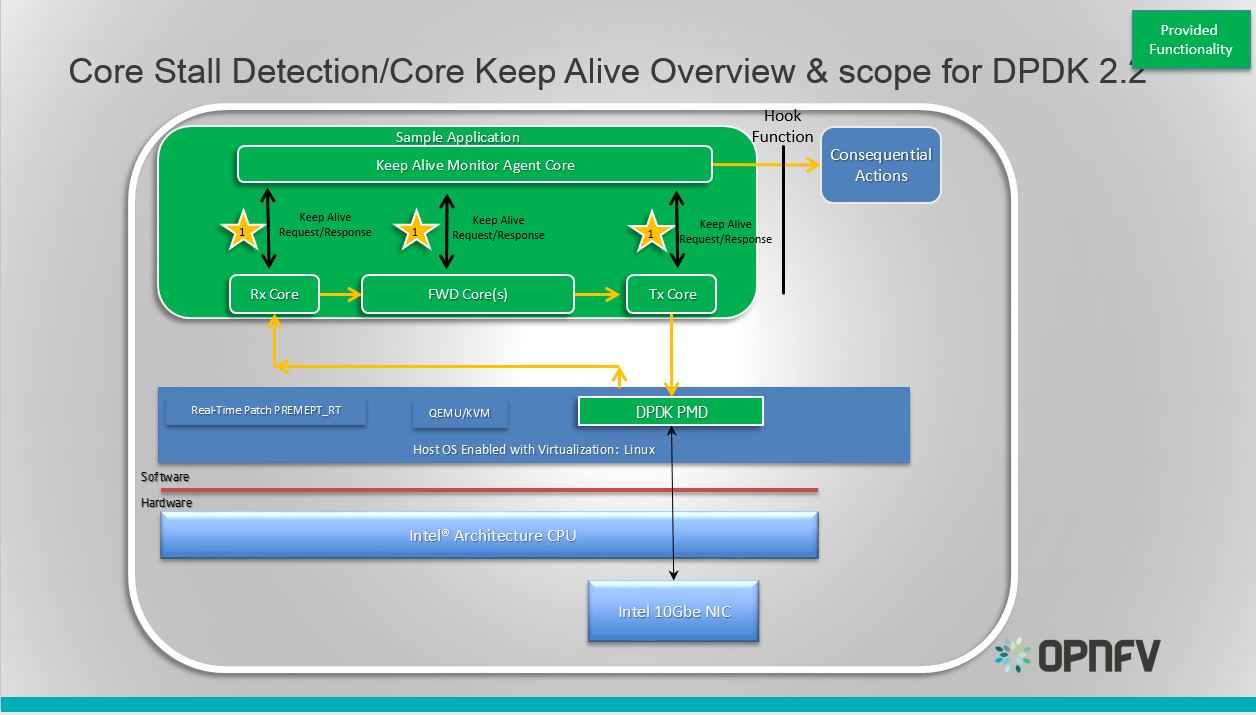
DPDK Keep Alive Sample Application
Essentially the app demonstrates how to detect ‘silent outages’ on DPDK packet processing cores. The application can be decomposed into two specific parts: detection and notification.
- The detection period is programmable/configurable but defaults to 5ms if no timeout is specified.
- The Notification support is enabled by simply having a hook function that where this can be ‘call back support’ for a fault management application with a compliant heartbeat mechanism.
DPDK Keep Alive Sample App Internals¶
This section provides some explanation of the The Keep-Alive/’Liveliness’ conceptual scheme as well as the DPDK Keep Alive App. The initialization and run-time paths are very similar to those of the L2 forwarding application (see L2 Forwarding Sample Application (in Real and Virtualized Environments) for more information).
There are two types of cores: a Keep Alive Monitor Agent Core (master DPDK core) and Worker cores (Tx/Rx/Forwarding cores). The Keep Alive Monitor Agent Core will supervise worker cores and report any failure (2 successive missed pings). The Keep-Alive/’Liveliness’ conceptual scheme is:
- DPDK worker cores mark their liveliness as they forward traffic.
- A Keep Alive Monitor Agent Core runs a function every N Milliseconds to inspect worker core liveliness.
- If keep-alive agent detects time-outs, it notifies the fault management entity through a call-back function.
Note: Only the worker cores state is monitored. There is no mechanism or agent to monitor the Keep Alive Monitor Agent Core.
DPDK Keep Alive Sample App Code Internals¶
The following section provides some explanation of the code aspects that are specific to the Keep Alive sample application.
The heartbeat functionality is initialized with a struct rte_heartbeat and the callback function to invoke in the case of a timeout.
rte_global_keepalive_info = rte_keepalive_create(&dead_core, NULL);
if (rte_global_hbeat_info == NULL)
rte_exit(EXIT_FAILURE, "keepalive_create() failed");
The function that issues the pings hbeat_dispatch_pings() is configured to run every check_period milliseconds.
if (rte_timer_reset(&hb_timer,
(check_period * rte_get_timer_hz()) / 1000,
PERIODICAL,
rte_lcore_id(),
&hbeat_dispatch_pings, rte_global_keepalive_info
) != 0 )
rte_exit(EXIT_FAILURE, "Keepalive setup failure.\n");
The rest of the initialization and run-time path follows the same paths as the the L2 forwarding application. The only addition to the main processing loop is the mark alive functionality and the example random failures.
rte_keepalive_mark_alive(&rte_global_hbeat_info);
cur_tsc = rte_rdtsc();
/* Die randomly within 7 secs for demo purposes.. */
if (cur_tsc - tsc_initial > tsc_lifetime)
break;
The rte_keepalive_mark_alive() function simply sets the core state to alive.
static inline void
rte_keepalive_mark_alive(struct rte_heartbeat *keepcfg)
{
keepcfg->state_flags[rte_lcore_id()] = 1;
}
Keep Alive Monitor Agent Core Monitoring Options The application can run on either a host or a guest. As such there are a number of options for monitoring the Keep Alive Monitor Agent Core through a Local Agent on the compute node:
Application Location DPDK KA LOCAL AGENT HOST X HOST/GUEST GUEST X HOST/GUEST
For the first implementation of a Local Agent SFQM will enable:
Application Location DPDK KA LOCAL AGENT HOST X HOST
Through extending the dpdkstat plugin for collectd with KA functionality, and integrating the extended plugin with Monasca for high performing, resilient, and scalable fault detection.